


At re:Invent 2025, we introduced serverless storage for Amazon EMR Serverless, eliminating the necessity to provision native disk storage for Apache Spark workloads. Serverless storage of Amazon EMR Serverless reduces information processing prices by as much as 20% whereas serving to forestall job failures from disk capability constraints.
On this submit, we discover the fee enhancements we noticed when benchmarking Apache Spark jobs with serverless storage on EMR Serverless. We take a deeper have a look at how serverless storage helps scale back prices for shuffle-heavy Spark workloads, and we define sensible steerage on figuring out the sorts of queries that may profit most from enabling serverless storage in your EMR Serverless Spark jobs.
Benchmark outcomes for EMR 7.12 with serverless storage in opposition to commonplace disks
We carried out the efficiency and value financial savings benchmarking utilizing the TPC-DS dataset at 3TB scale, operating 100+ queries that included a mixture of excessive and low shuffle operations. The take a look at configuration utilized Dynamic Useful resource Allocation (DRA) with no pre-initialized capability. The system was arrange with 20GB of disk area, and Spark configurations included 4 cores and 14GB reminiscence for each driver and executor, with dynamic allocation beginning at 3 preliminary executors (spark.dynamicAllocation.initialExecutors = 3). A comparative evaluation was carried out between native disk storage and serverless storage configurations. The goal was to evaluate each complete and common price implications between these storage approaches.
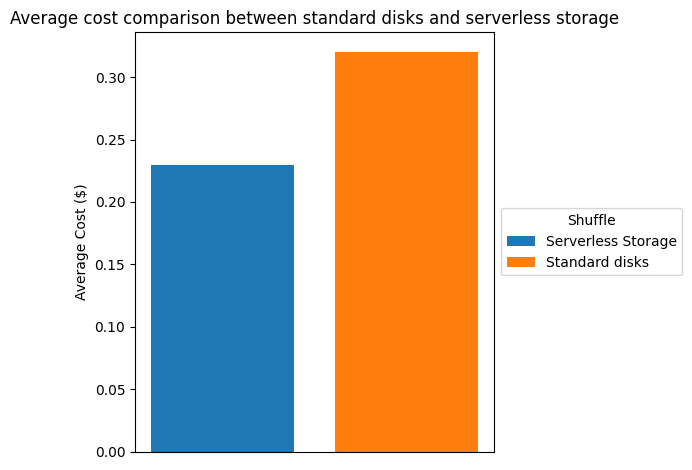
The next desk and chart evaluate the fee discount we noticed within the testing setting described above. Primarily based on us-east-1 pricing, we noticed a value financial savings of greater than 26% when utilizing serverless storage.
| Shuffle | |||
| serverless storage | commonplace Disks | financial savings | |
| Complete Price ($) | 24.28 | 33.1 | 26.65% |
| Common Price ($) | 0.233 | 0.318 | 26.73% |
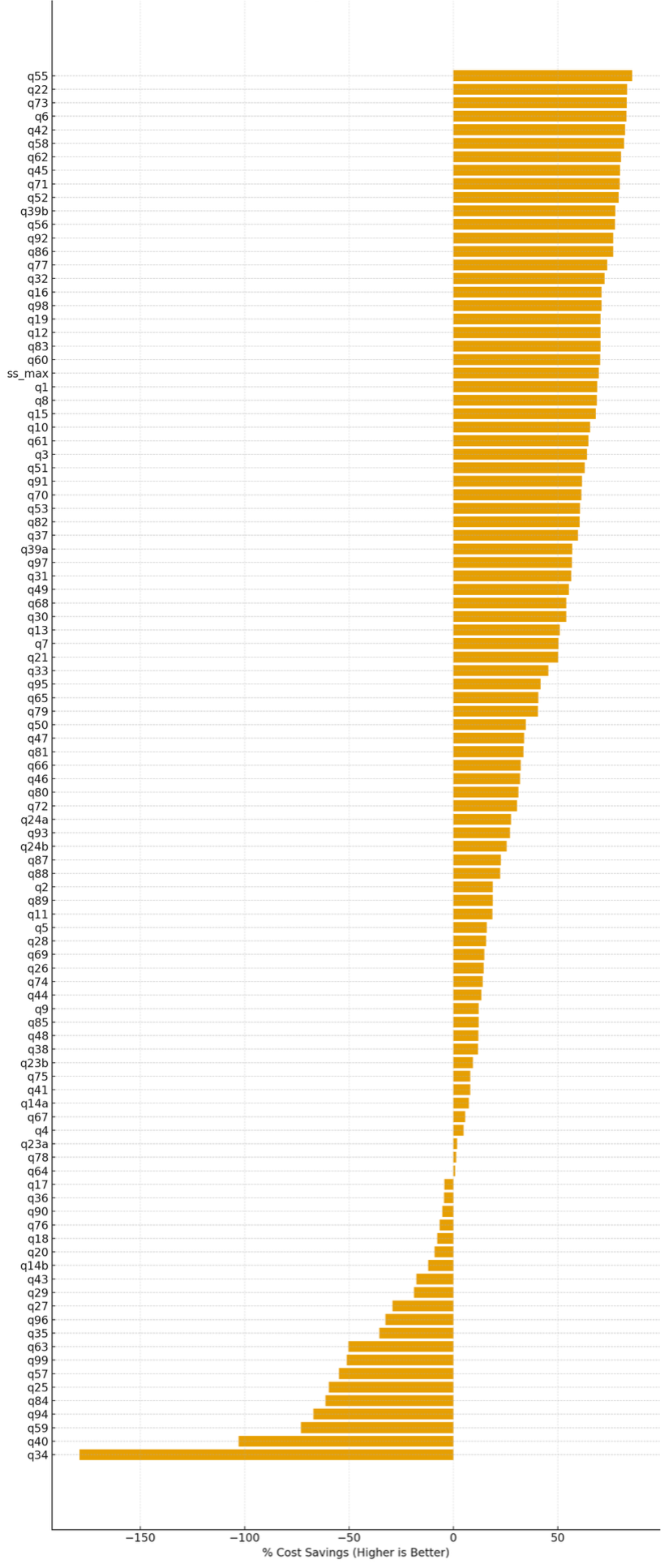
% Relative financial savings (per question) of serverless storage in comparison with commonplace disk shuffle
On this testing, we noticed that serverless storage in EMR Serverless reduces price for about 80% of TPC-DS queries. For the queries the place it gives advantages, it delivers a median price saving of roughly 47%, with financial savings of as much as 85%. Queries that regress sometimes have low shuffle depth, preserve excessive parallelism all through execution, or full shortly sufficient that executor scale-down alternatives are minimal. The next determine reveals the share price distinction for every of the TPC-DS queries when serverless storage was enabled, in comparison with the baseline configuration with out serverless storage. Constructive values point out price financial savings (increased is healthier), whereas damaging values point out price regressions.
Share price financial savings per TPC-DS question with serverless storage enabled
Runtime comparability
There’s important price financial savings because of the elevated elasticity from terminating executors earlier. Nonetheless, job completion time might improve as a result of the shuffle information is saved in serverless storage somewhat than domestically on the executors. The extra learn and write latency for shuffle information contributes to the longer runtime. The next desk and chart present the runtime comparability, we noticed in our testing setting.
| Shuffle | |||
| serverless storage | commonplace disks | runtime | |
| Complete Length (sec) | 6770.63 | 4908.52 | -37.94% |
| Common Length (sec) | 65.1 | 47.2 | -37.92% |
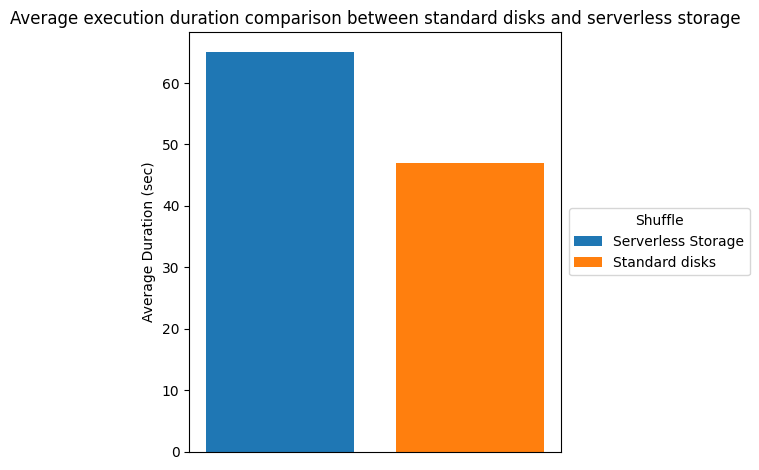
Storing shuffle externally and decoupling from the compute allowed the pliability for EMR Serverless to show off unused assets dynamically because the state data has been offloaded from the compute. Nonetheless, these price financial savings may be realized solely when DRA is on. If DRA is turned off, Spark would hold these unused assets alive including to the overall price.
Question patterns that profit from serverless storage
The associated fee financial savings from serverless storage rely closely on how executor demand modifications throughout levels of a job. On this part, we look at frequent execution patterns and clarify which question shapes are probably to learn from serverless storage of EMR Serverless and which question patterns might not profit from shuffle externalization.
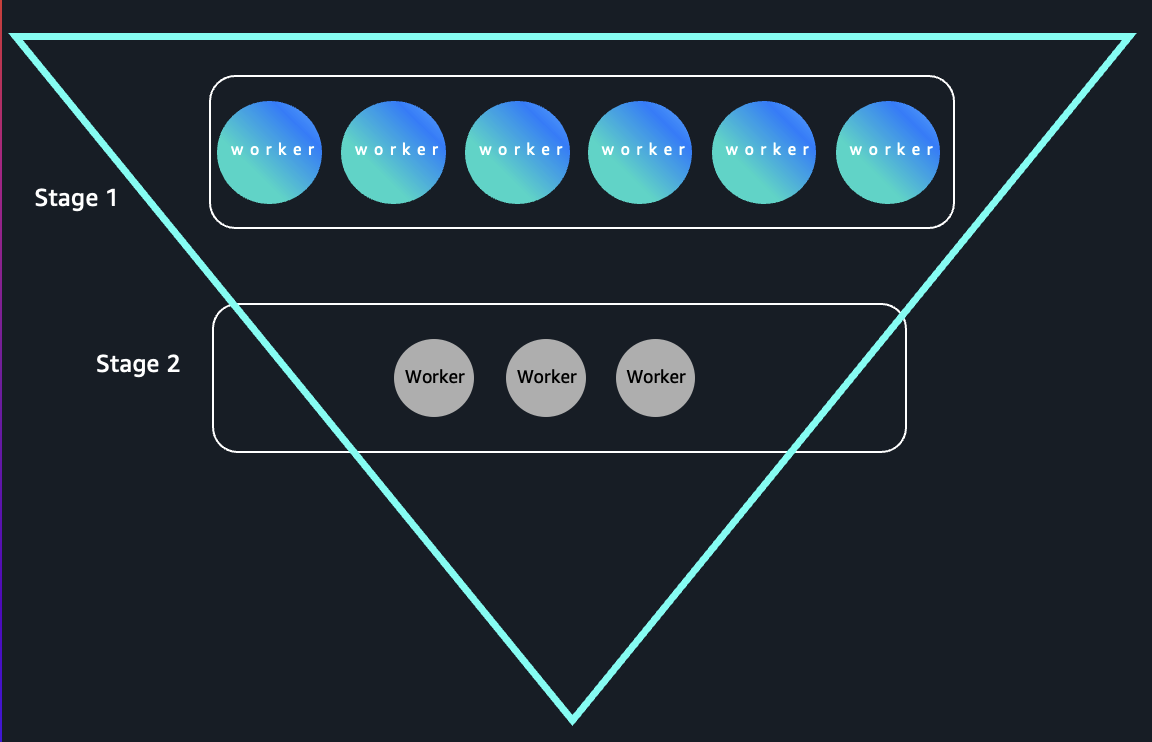
Inverted triangle sample queries
So as to perceive why externalizing the shuffle information can permit such a big price financial savings, contemplate a simplified question. The next question calculates annual complete gross sales from the TPC-DS dataset by becoming a member of the store_sales and date_dim tables, summing the gross sales quantities per 12 months, and ordering the outcomes.
This question demonstrates that top executor demand throughout the map part and low executor demand within the scale back part is an aggregation question with a excessive cardinality enter and a low cardinality group by.
- Stage 1 (Excessive Executor Demand)
The be part of and skim steps scan the complete store_sales and date_dim tables. This usually entails billions of rows in large-scale TPC-DS datasets, so Spark will attempt to parallelize the scan throughout many executors to maximise learn throughput and compute effectivity.
- Stage 2 (Low Executor Demand)
The aggregation is on d_year, which generally has few distinctive values, resembling solely a handful of years within the information. This implies after the shuffle stage, the scale back part combines the partial aggregates into a variety of keys equal to the variety of years (usually < 10). Just a few Spark duties are wanted to complete the ultimate aggregation, so most executors turn into idle.
With shuffle info saved on the native disk, the compute assets related to these idle executors would nonetheless be operating as a way to hold the shuffle information accessible. With shuffle information offloaded from the nodes operating the executors, with DRA enabled, these nodes with idle executors get launched instantly.
As a result of early levels course of high-cardinality inputs and later levels collapse information right into a small variety of keys, these queries kind an “inverted triangle” execution sample: vast parallelism on the prime and slim parallelism on the backside as proven within the following picture:
Hourglass sample queries
Relying upon the complexity of the job, there may be a number of levels with various demand on variety of executors wanted for the stage. Such jobs can profit from better elasticity obtained by offloading shuffle information to exterior serverless storage. One such sample is the hour glass sample. The next determine reveals a workload sample the place executor demand expands, contracts throughout shuffle-heavy levels, and expands once more. Serverless storage of EMR Serverless decouples shuffle information from compute, enabling extra environment friendly scale-down throughout slim levels and serving to enhance price optimization for elastic workloads.
Hourglass sample in Spark stage execution
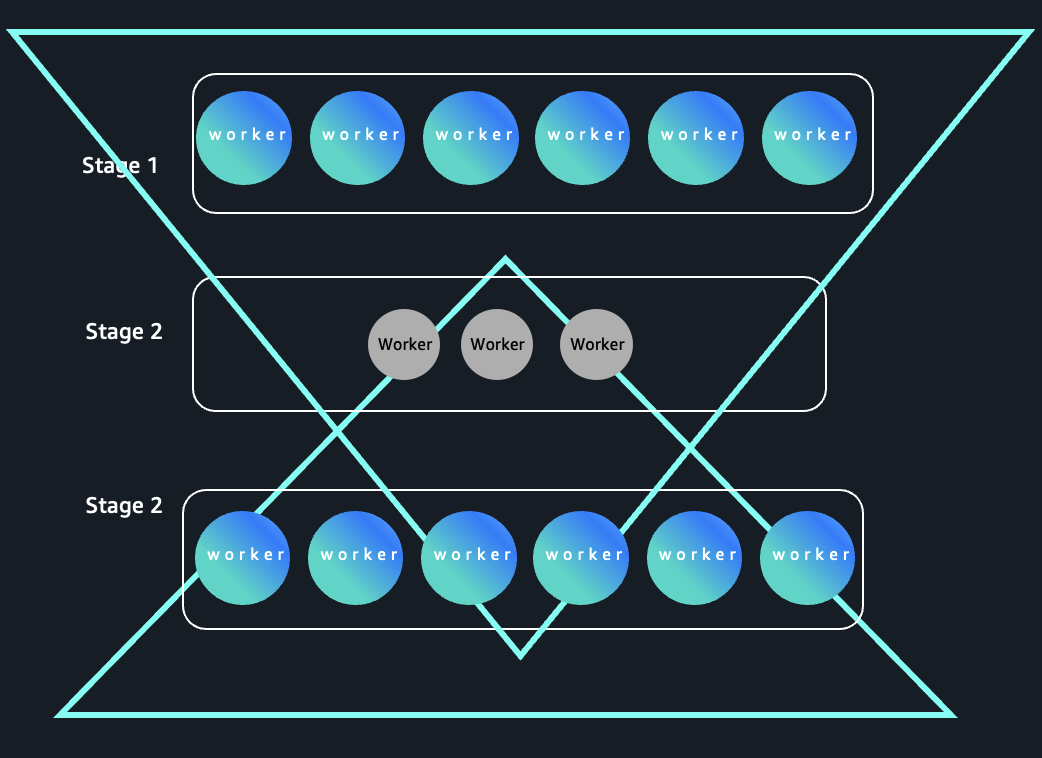
To determine queries of this class, contemplate the next instance, The question progresses via three levels:
- Stage 1: The preliminary be part of and filter between
store_salesandmerchandiseproduces a large, high-cardinality intermediate dataset, requiring excessive parallelism (many executors). - Stage 2: Aggregation teams by a small set of classes resembling “Dwelling” or “Electronics”, leading to a drastic drop in output partitions. So this stage effectively runs with just a few executors, as there’s little information to parallelize.
- Stage 3: The small result’s joined (often a broadcast be part of) again to a big reality desk with a date dimension, once more producing a big consequence that’s well-parallelized, inflicting Spark to ramp up executor utilization for this stage.
This sample is frequent for reporting and dimensional evaluation eventualities and is efficient for demonstrating how Spark dynamically adjusts useful resource utilization throughout job levels primarily based on cardinality and parallelism wants. Such queries can even profit from the elasticity enabled by exterior serverless storage.
Rectangle sample queries
Not all queries profit from externalizing the shuffle. Contemplate a question the place the cardinality is excessive all through, which means each the levels function on numerous partitions and keys. Usually, queries that group by high-cardinality columns (resembling merchandise or buyer) trigger most levels to require related quantities of parallelism. The next determine illustrates a Spark workload the place parallelism stays constantly excessive throughout levels. On this sample, each Stage 1 and Stage 2 function on numerous partitions and keys, leading to sustained executor demand all through the job lifecycle.
Excessive-cardinality execution sample with sustained parallelism
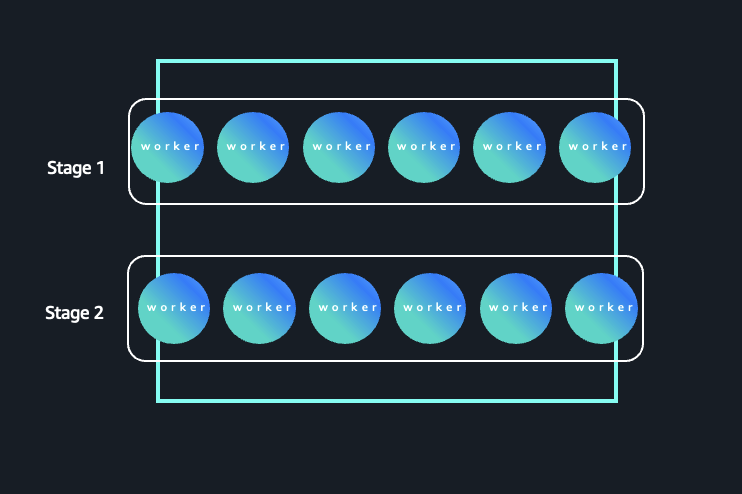
The next question is similar question that we used within the inverted triangle sample earlier, with one change. Now we have changed the dim_date desk (low cardinality) with merchandise (excessive cardinality).
- Stage 1: Reads the rows from
store_salesand joins withmerchandise, spreading information throughout many partitions—just like the unique question’s first stage. - Stage 2: The aggregation is by
i_item_id, which usually has 1000’s to thousands and thousands of distinct values in actual datasets. This retains parallelism excessive; many duties deal with non-overlapping keys, and shuffle outputs stay massive.
There is no such thing as a important drop in cardinality: As a result of neither stage is lowered to a small group set, most executors keep busy all through the job’s most important phases, with little idle time even after the shuffle. This kind of question leads to a flatter executor utilization profile as a result of every stage processes an identical quantity of labor, thus minimizing variation in useful resource utilization. These rectangle sample queries is not going to see the fee profit from the elasticity obtained by offloading shuffle information. Nonetheless, there should be different advantages resembling discount of job failures and efficiency bottlenecks from disk constraints, freedom from capability planning and sizing, and provisioning of storage for intermediate information operations.
Conclusion
Serverless storage for Amazon EMR Serverless can ship substantial price financial savings for workloads with dynamic useful resource patterns, as seen within the 26% common price financial savings we noticed in our testing setting. By externalizing shuffle information, you possibly can acquire the elasticity to launch idle executors instantly, demonstrated by the financial savings reaching as much as 85% in our testing setting, on queries following inverted triangle and hourglass patterns when Dynamic Useful resource Allocation is enabled.Understanding your workload traits is vital. Whereas rectangle sample queries might not see dramatic price reductions, they’ll nonetheless profit from improved reliability and elimination of capability planning overhead.
To get began: Analyze your job execution patterns, allow Dynamic Useful resource Allocation, and pilot serverless storage on shuffle-heavy workloads. Seeking to scale back your Amazon EMR Serverless prices for Spark workloads? Discover serverless storage for EMR Serverless at this time.
Concerning the authors

{kind=link}