


GPUs energy right now’s most superior AI workloads—from forecasting and proposals to multimodal basis fashions. Nonetheless, groups battle with procuring and managing GPU infrastructure, configuring distributed coaching environments, and debugging information loading bottlenecks. Deep studying researchers choose to give attention to the modeling, not troubleshooting infrastructure.
We’re excited to announce the Public Preview of AI Runtime (AIR), a brand new coaching stack that allows on-demand distributed GPU coaching on A10s and H100s. AI Runtime accommodates all of the know-how used for giant scale coaching of LLMs comparable to MPT and DBRX. Even in Beta, a number of a whole lot of consumers, together with Rivian, Factset, and YipitData have used AIR to coach and ship deep studying fashions into manufacturing. Use instances span the gamut from pc imaginative and prescient fashions to advice programs to finetuned LLMs for agentic duties. Our personal Databricks AI Analysis staff used AIR for reinforcement studying of fashions comparable to in our current KARL paper.
With AI Runtime, Databricks customers now have:
- Serverless, on-demand NVIDIA GPUs: Merely configure your pocket book in 2-3 clicks, and get quick connect to Serverless A10 and H100 GPUs to start out coaching – no cluster wanted. Solely pay for the GPUs that you just use, with out worrying about idle time utilization.
- Sturdy orchestration instruments: Use the complete energy of Databricks’ orchestration suite with Lakeflow Jobs and DABs assist for long-running GPU workloads
- Optimized distributed coaching: AIR bundles distributed GPU efficiency enhancements, like RDMA and high-performance information loading
- Centralized governance and observability: run, observe, and govern GPU workloads precisely the place your information resides, with inbuilt experiment administration by way of MLflow, entry administration with Unity Catalog, and agent-assisted debugging
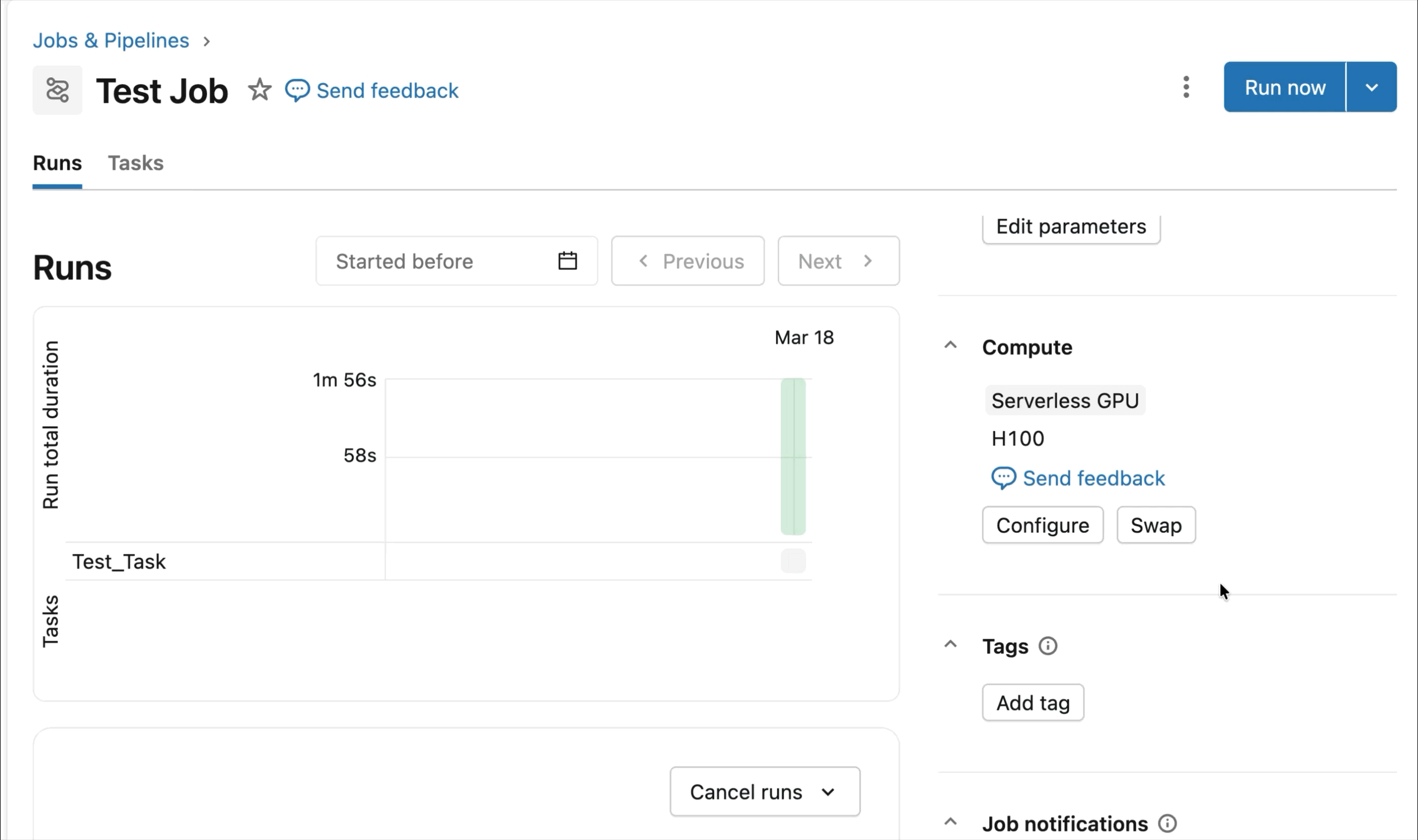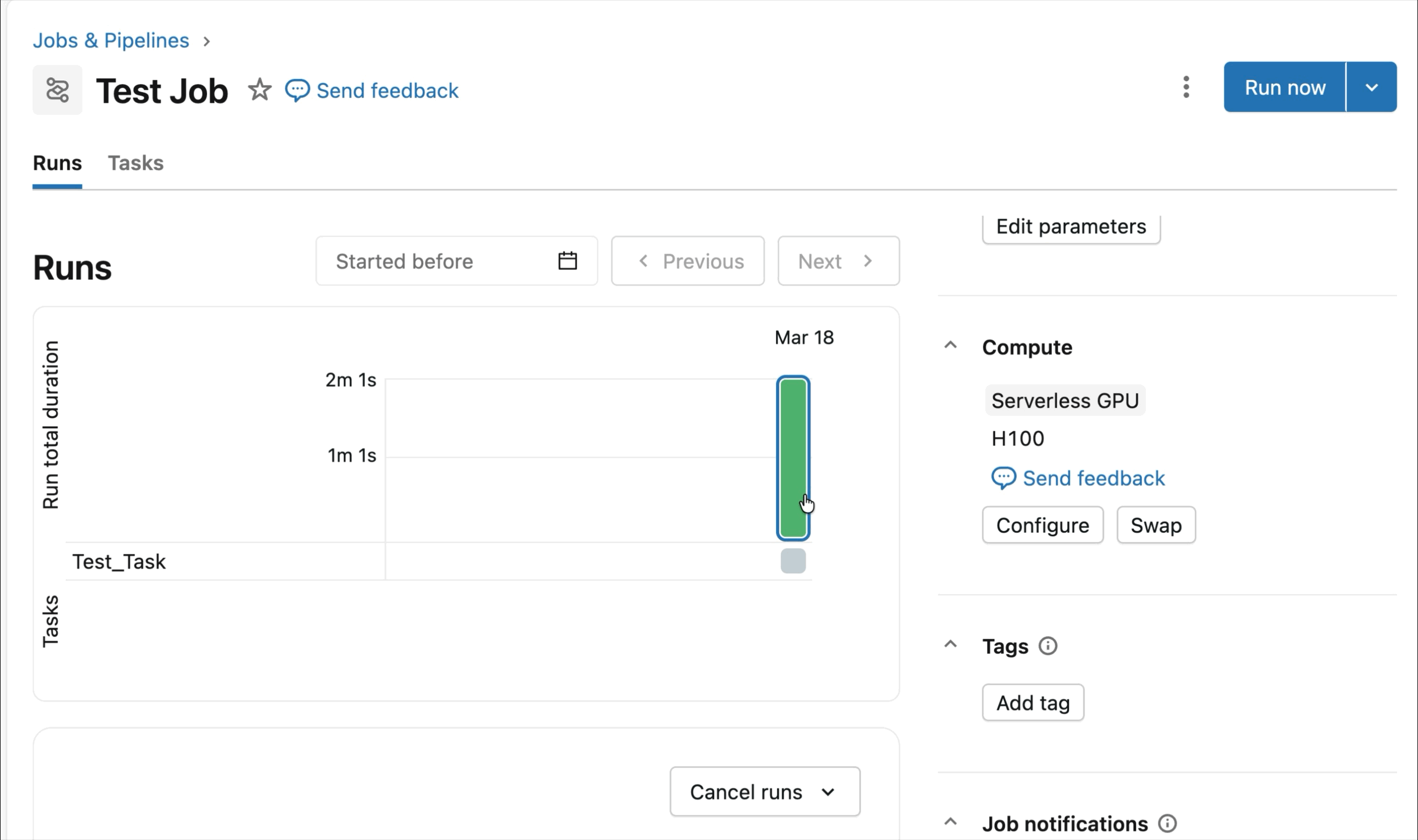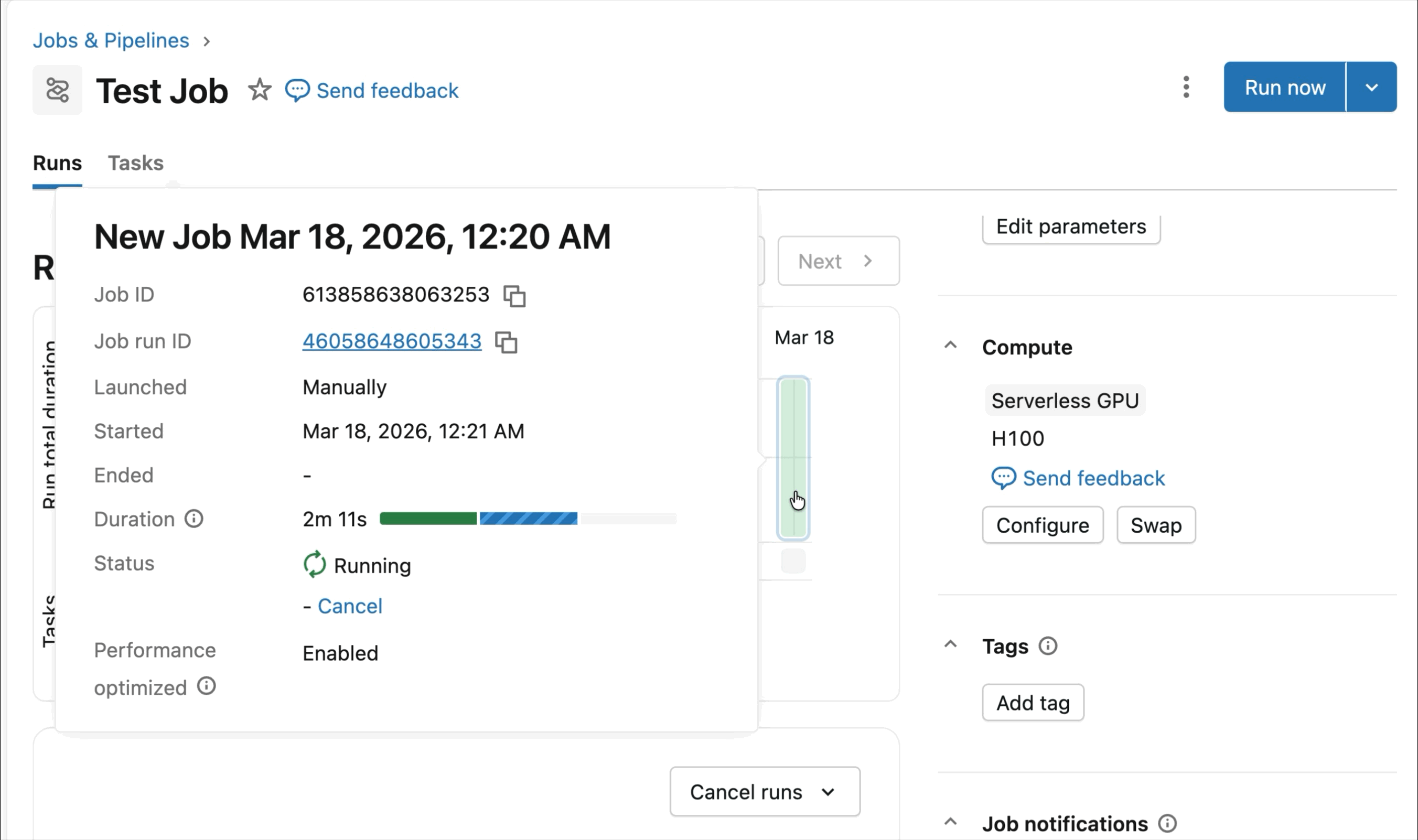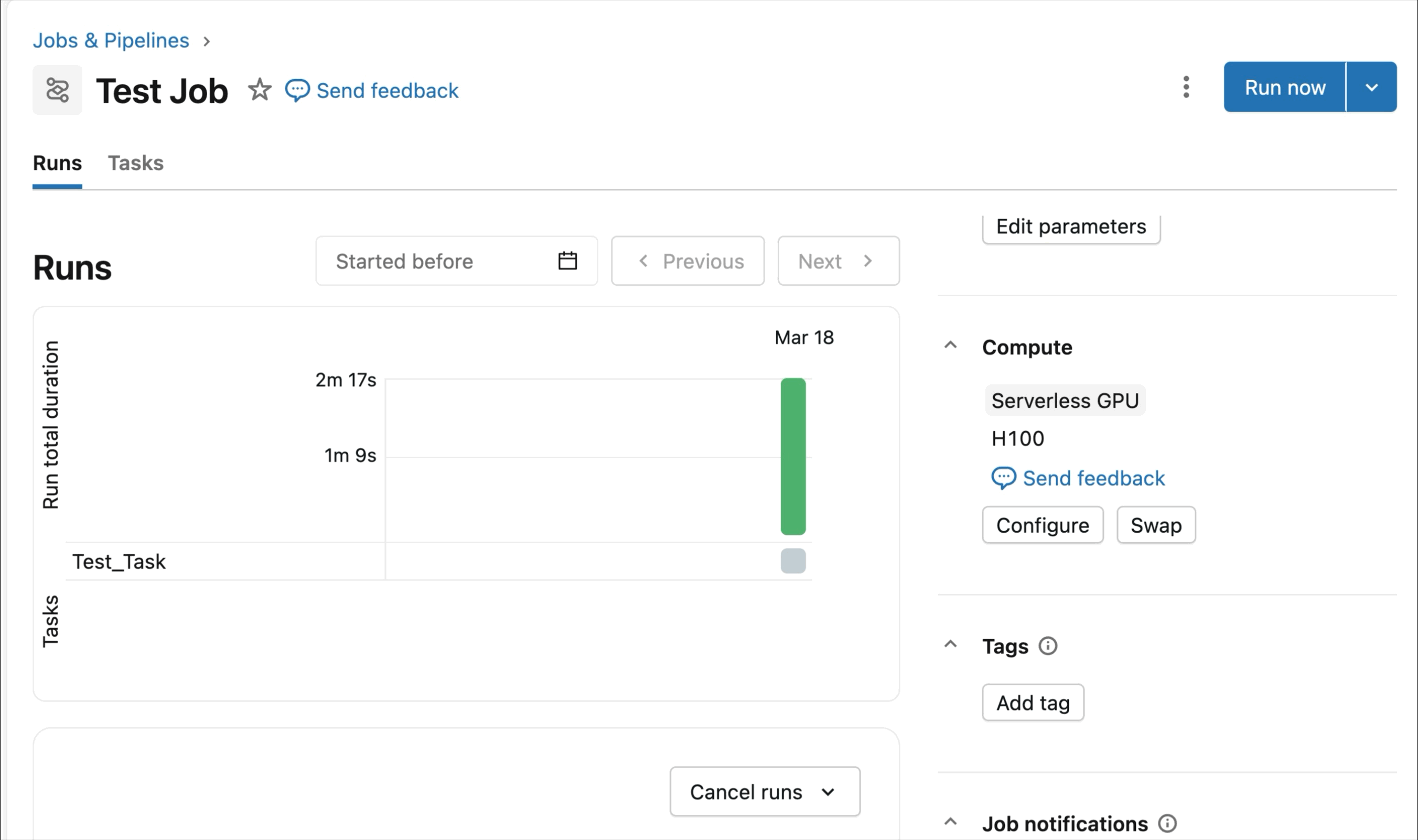
On-demand NVIDIA H100 and A10 GPUs in notebooks
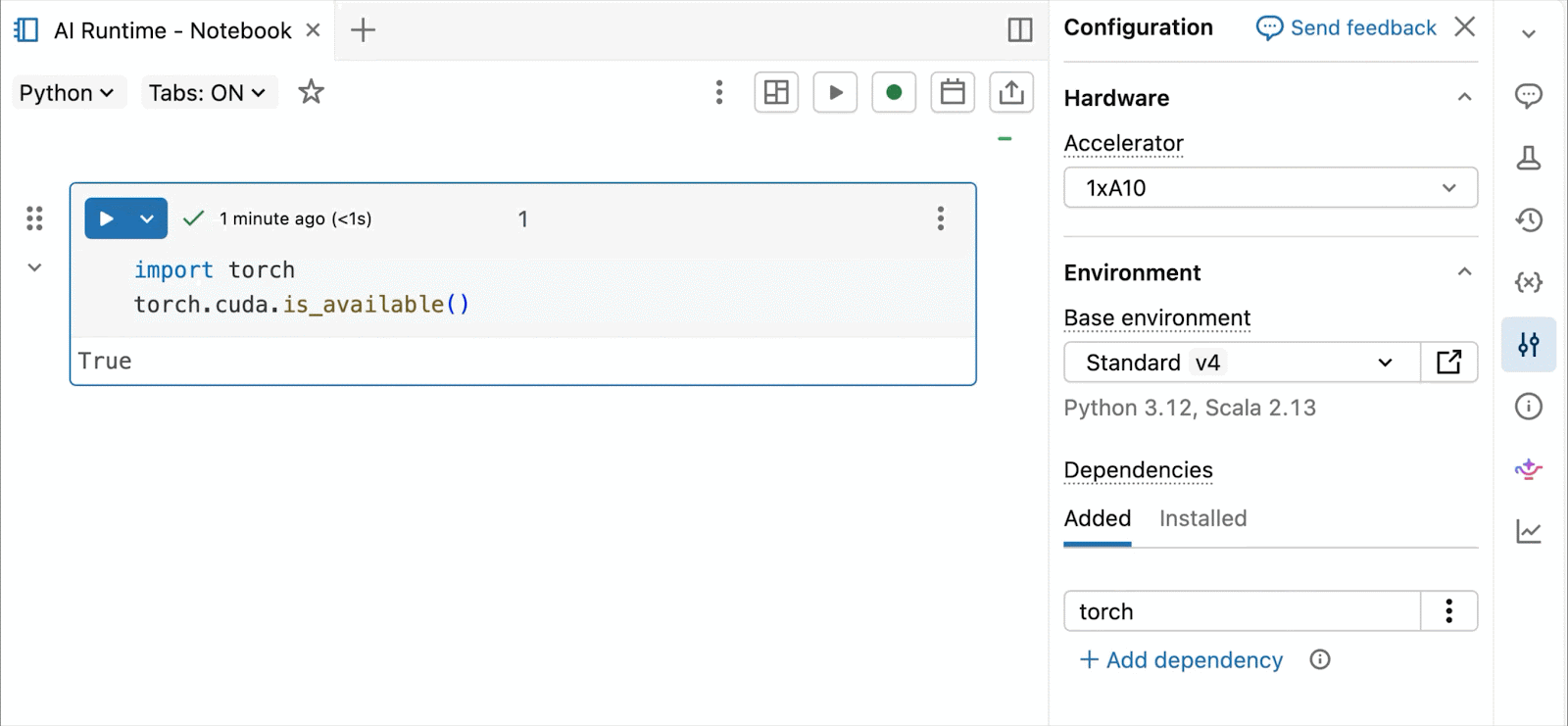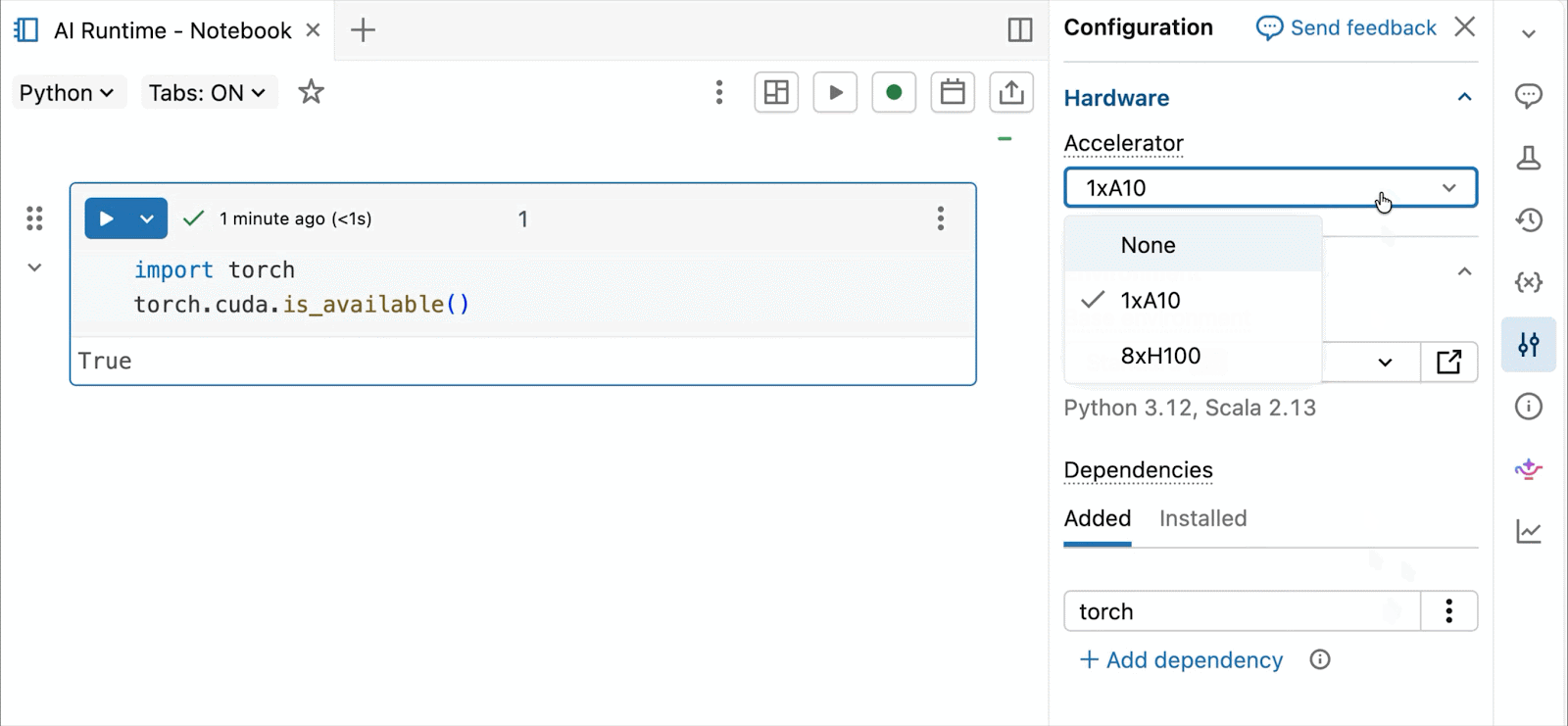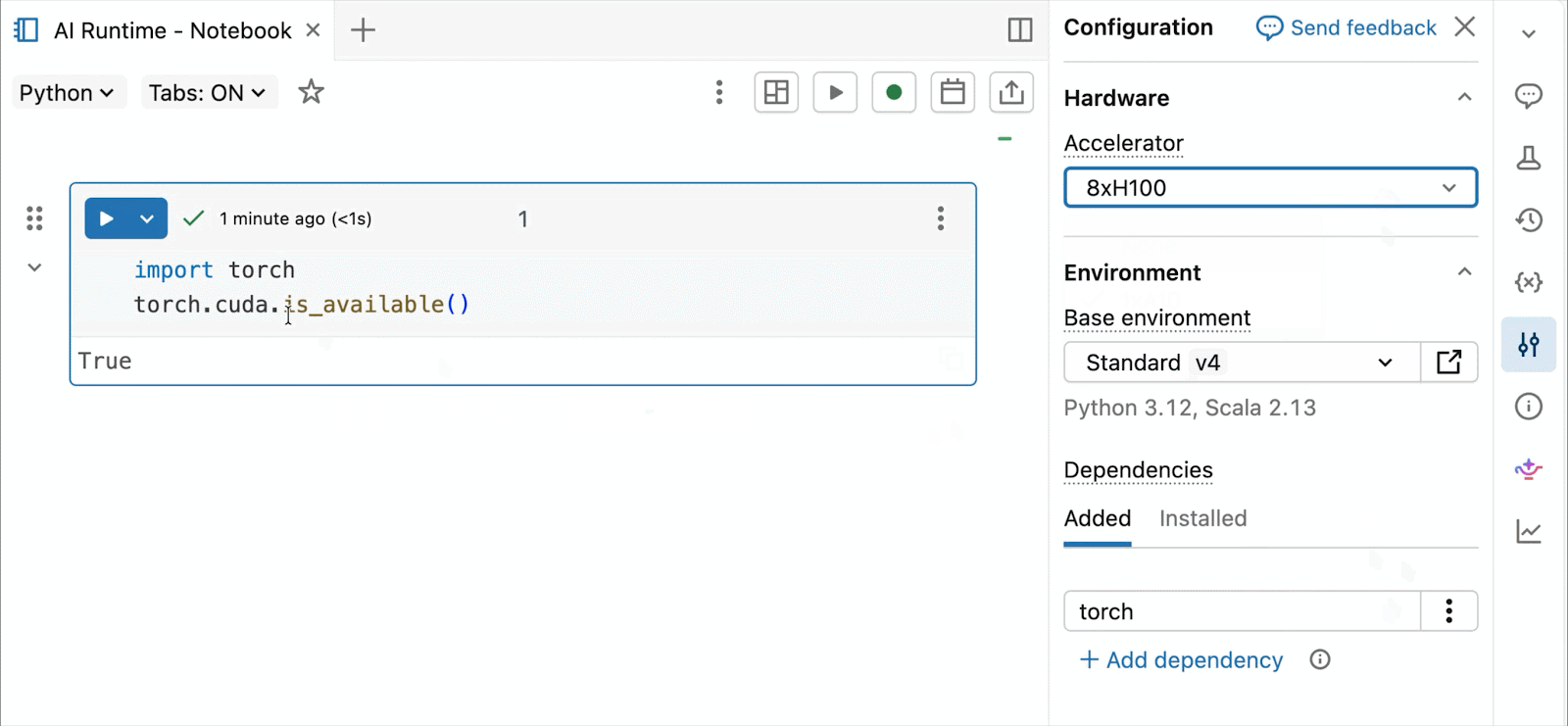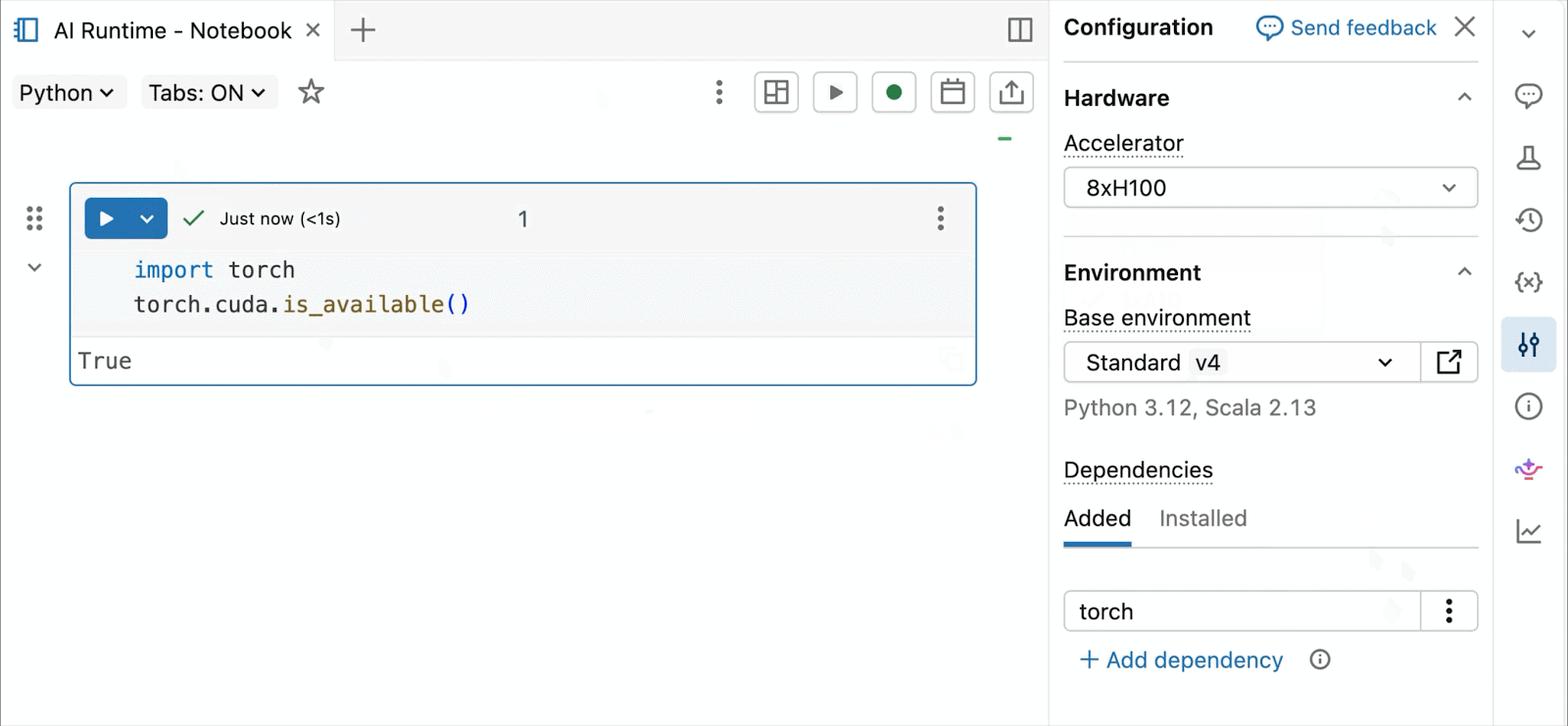
For interactive improvement and debugging, connect with on-demand A10s and H100s in Databricks Notebooks with just some clicks. From there, leverage all of the developer ergonomics that Databricks is thought for, from atmosphere administration for frequent Python packages to agent-powered authoring and debugging with Genie Code. Simply mount information from the Lakehouse to coach deep studying fashions, and even invoke a fleet of distant CPUs for Spark information processing workloads out of your GPU-powered pocket book to organize your information.
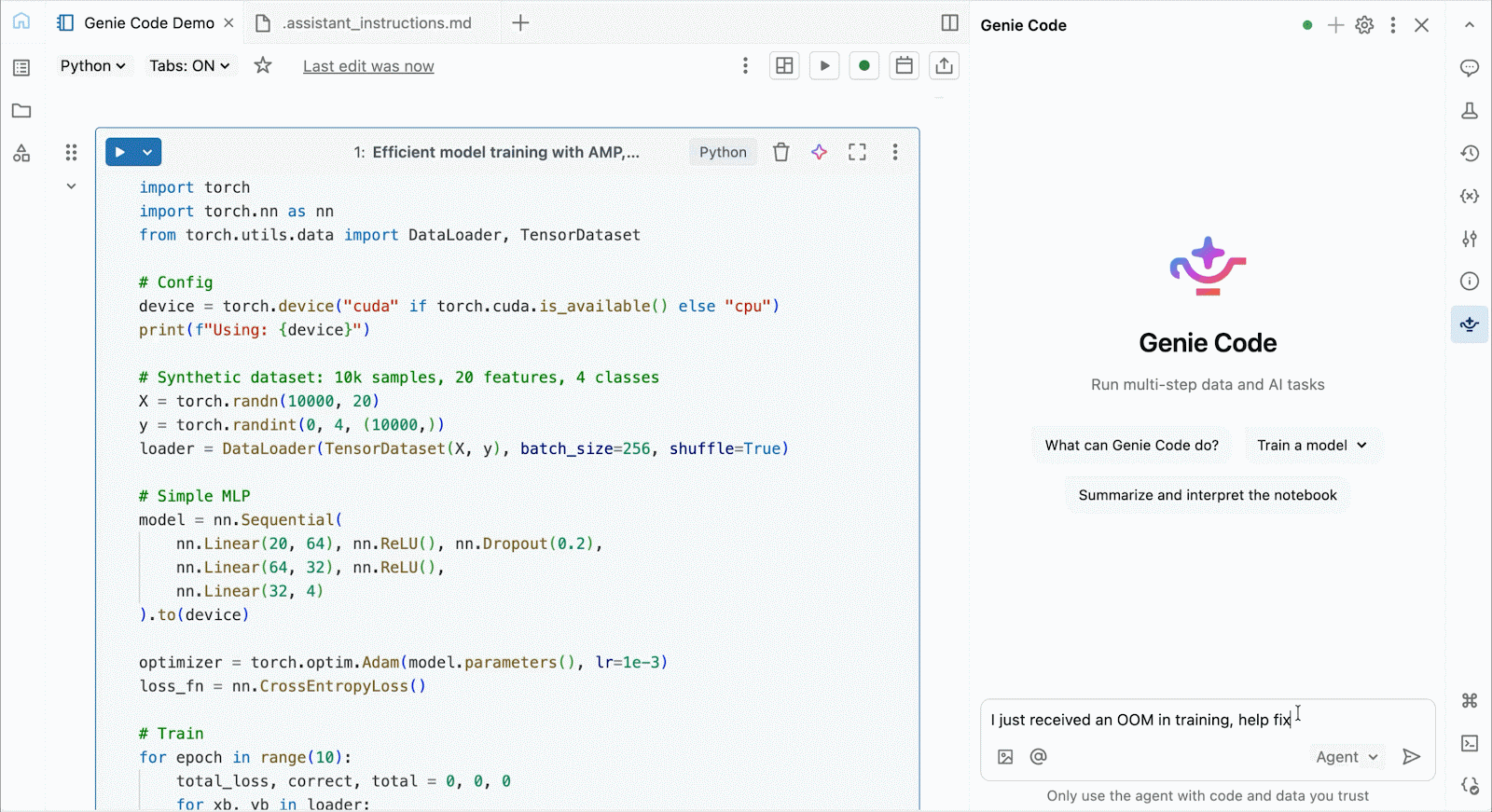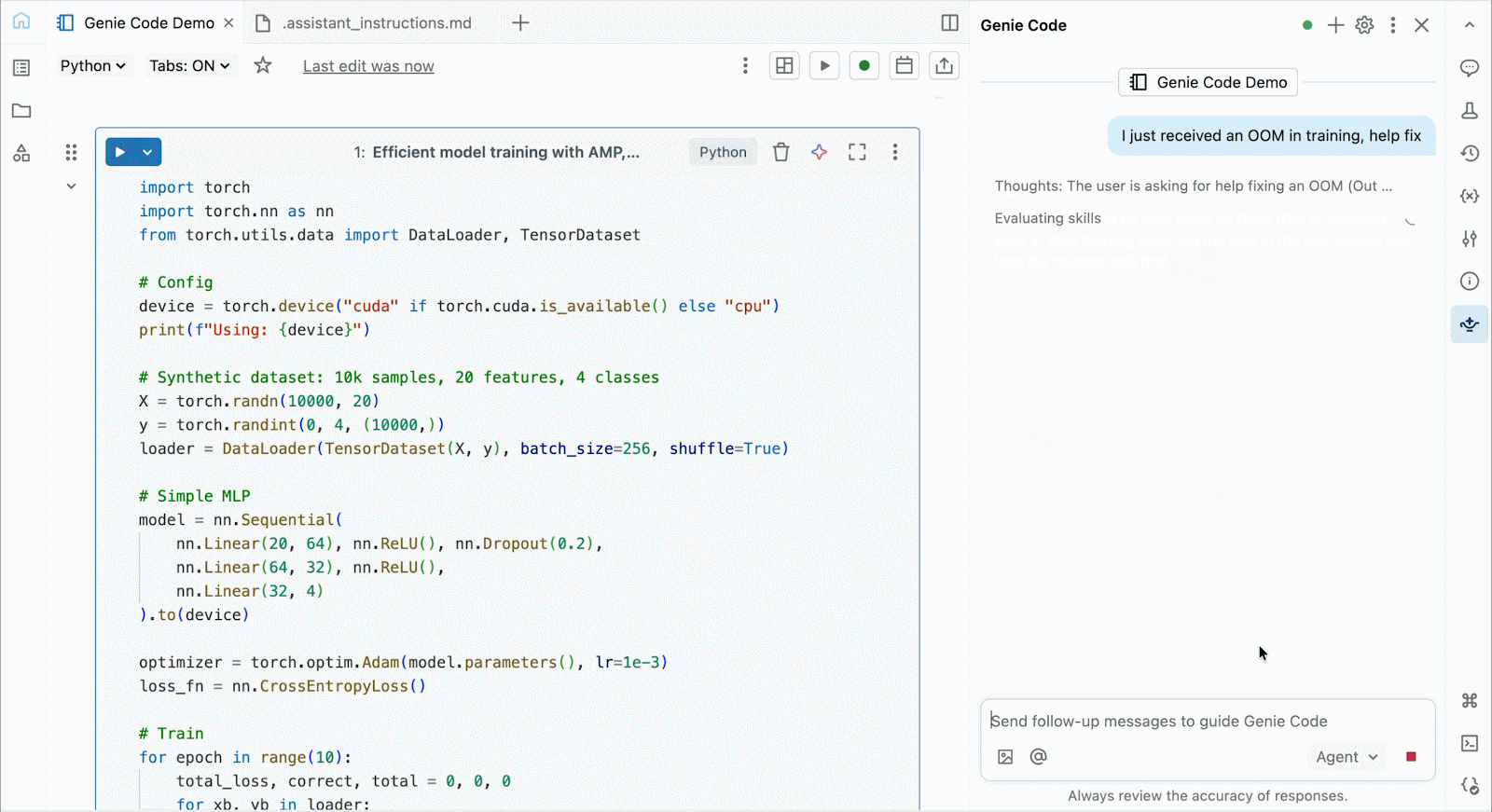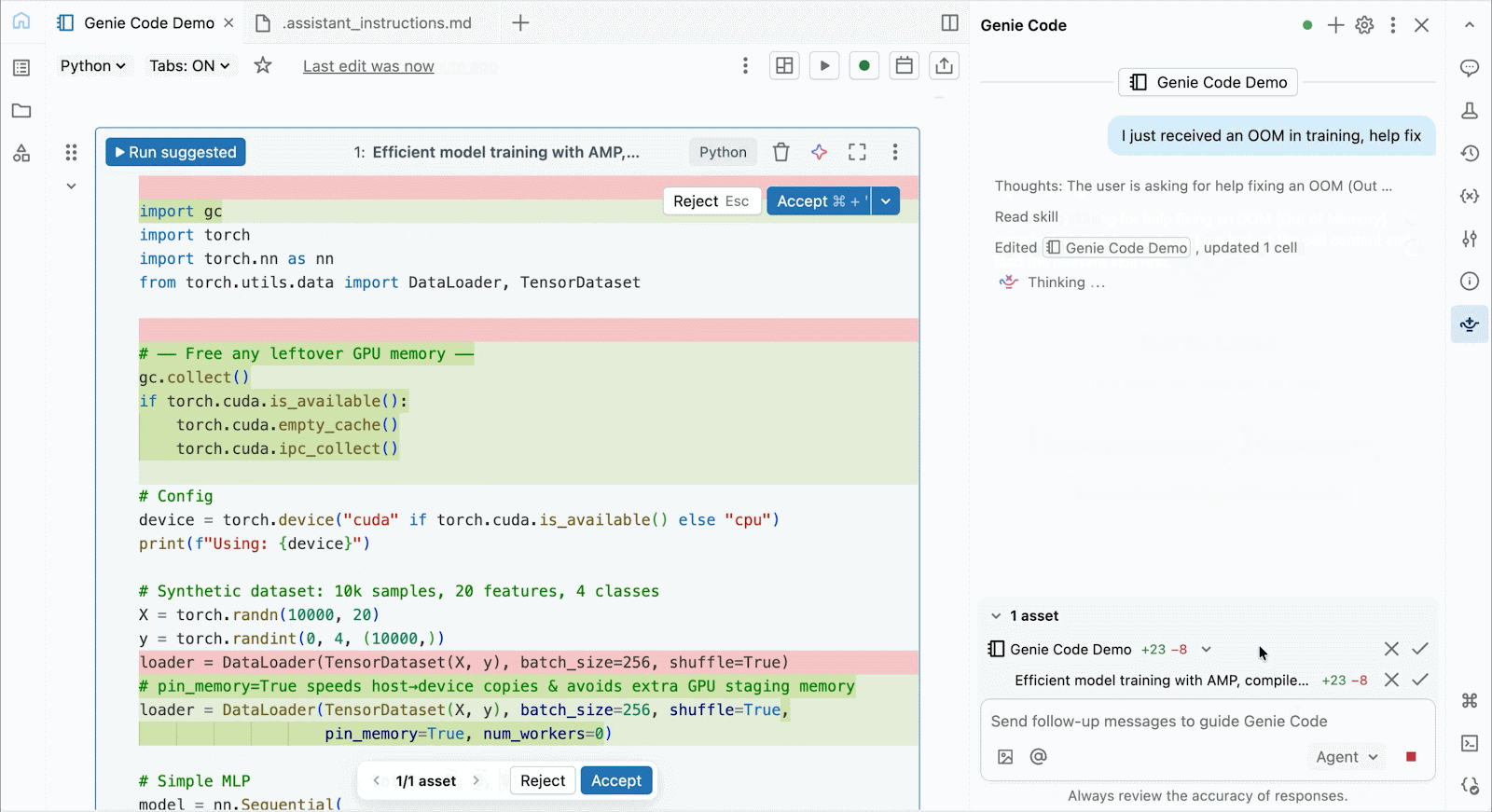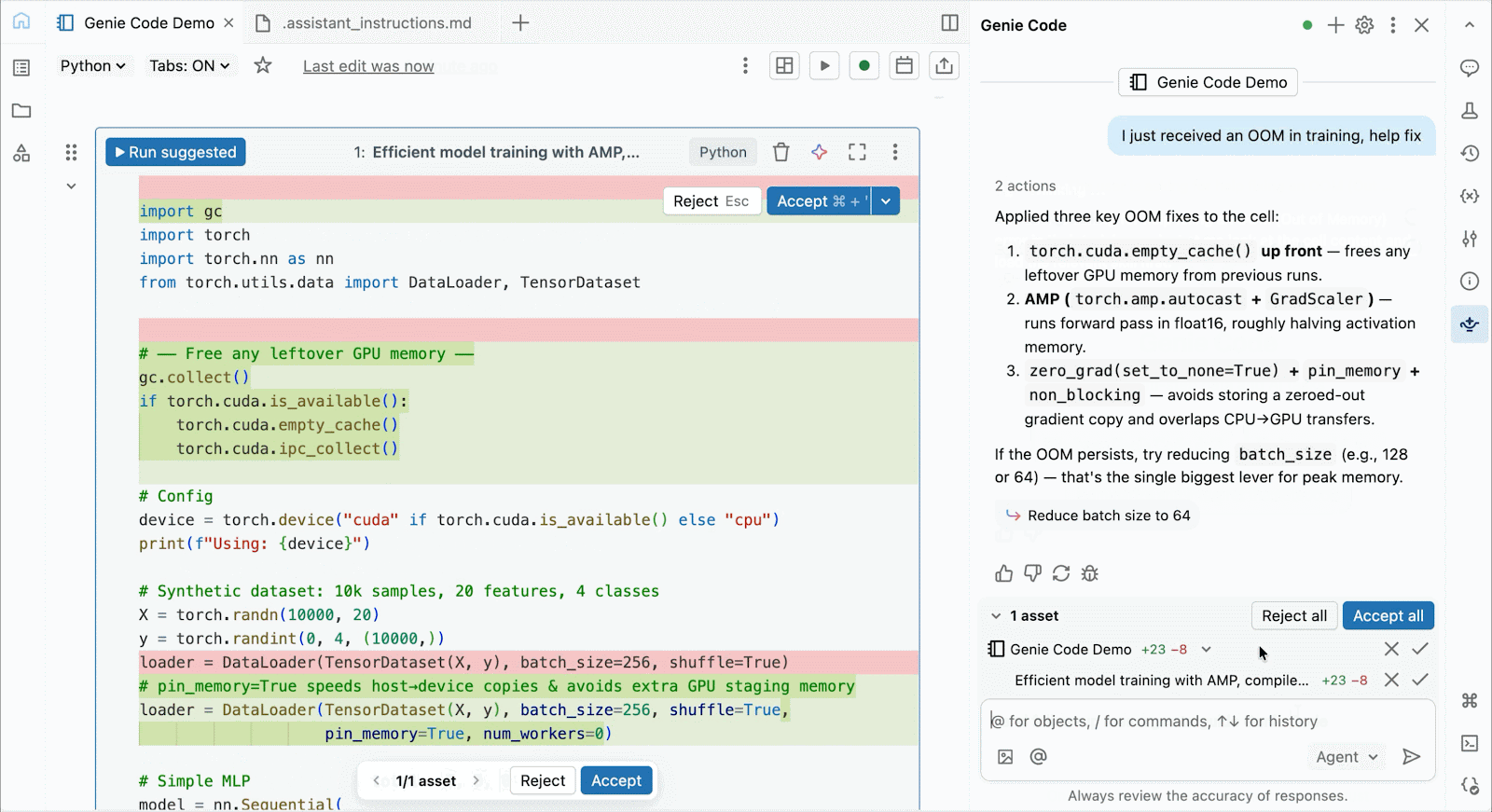
Use Genie Code to assist resolve efficiency bottlenecks, experiment with new architectures, or debug tough bugs round mannequin convergence or cryptic framework errors.
Lakeflow for production-ready workloads
AI Runtime is a production-grade platform for accelerated computing. Develop your deep studying code in interactive notebooks, after which use the complete energy of Lakeflow to submit and orchestrate jobs on GPU compute. Each notebooks and customized code repositories could be executed by Lakeflow for long-running or scheduled jobs. For manufacturing wants comparable to CI/CD (steady integration and steady deployment), AI Runtime is absolutely appropriate with our Declarative Automation Bundles (DABs).
With our Lakeflow integration, clients can preserve mannequin coaching and fine-tuning tightly synchronized with upstream information pipelines and downstream manufacturing programs.
“Databricks’ AI Runtime vastly streamlined the method of coaching a customized Textual content To Method (TTF) mannequin. With no infrastructure setup or delays, it was simple to decide on the appropriate compute based mostly on immediate measurement and output token technology. This allowed us to maneuver rapidly, preserve our Lakehouse workflows, and ship a high-quality mannequin with full governance, decreasing time to setup, prepare and deploy our mannequin from days to hours.”— Nikhil Sunderraj Principal Machine Studying Engineer, FactSet Analysis Methods, Inc.
Runtime optimized for distributed deep studying
Distributed coaching workloads could be painful to organize, debug, and observe. From troubleshooting RDMA setups to monitoring telemetry from a number of GPUs to correct software program configuration, customers can simply miss crucial particulars that dramatically sluggish mannequin coaching.
As a substitute, AI Runtime is optimized for the whole deep studying lifecycle—and is designed to save lots of you time. Key dependencies like PyTorch and CUDA come pre-installed, together with optimized assist for distributed coaching frameworks comparable to Ray, Hugging Face Transformers, Composer, and different libraries, so you can begin coaching instantly with out managing environments. Clients are additionally welcome to deliver their very own libraries, from Unsloth to TorchRec to customized coaching loops.

Built-in SDKs and observability instruments simplify the administration of distributed coaching workloads. MLFlow allows deep observability of GPU workloads, with computerized monitoring of GPU utilization and coaching experiments. Whether or not you are fine-tuning basis fashions or coaching forecasting and personalization fashions, the runtime is optimized to speed up coaching workflows with minimal setup.
At present’s Public Preview of AI Runtime helps distributed coaching throughout 8x H100s in a single-node, with multi-node assist at present in Non-public Preview.
“Databricks’ AI Runtime allows us to effectively run LLM workloads (advantageous tuning and inference) with out infrastructure overhead, immediately in our lakehouse. This seamless integration simplifies our pipelines and supplies environment friendly use of GPUs, enabling us to ship top quality AI insights to our clients and give attention to innovation, not on infrastructure.”— Lucas Froguel, Senior AI Platform Engineer, YipitData
Centralized information governance and observability
AI Runtime integrates natively with the Databricks Lakehouse, enabling you to run and govern GPU workloads the place your information resides. This eliminates fragmented workflows and simplifies the trail from experimentation to manufacturing.
- Centralized governance with Unity Catalog: Apply constant entry controls, lineage, and governance insurance policies throughout each information and AI workloads, enabling safe and compliant use of GPU assets.
- Unified observability: Monitor and monitor all workloads—CPU and GPU—in a single place utilizing native system tables for unified auditing, utilization monitoring, and operational insights.
Your AI workloads run absolutely inside your enterprise information perimeter, delivering sturdy governance and safety with out sacrificing flexibility for experimentation and scale.
“Leveraging Databricks’ serverless GPU assist inside our Lakehouse allows us to effectively prepare superior audio and multimodal fashions with out infrastructure overhead. This seamless integration simplifies workflows and supplies environment friendly use of GPU assets, making certain we ship high-performance programs and give attention to innovation.”— Arjuna Siva, VP of Infotainment & Connectivity, Rivian and Volkswagen Group Applied sciences
Integrating Subsequent-Era GPU Innovation From NVIDIA
Demand for accelerated compute continues to develop throughout AI workloads and agentic programs. AI Runtime allows extra Databricks clients to leverage NVIDIA {hardware} to speed up their AI workloads and drive their enterprise ahead. We’re excited to proceed partnering with NVIDIA to deliver the newest NVIDIA know-how, just like the RTX PRO 4500 Blackwell Server Version, introduced at GTC 2026 to our clients.
“As AI adoption accelerates throughout industries, organizations want scalable, high-performance infrastructure to energy their information and AI workloads. NVIDIA applied sciences deliver accelerated efficiency to the AI Runtime providing for the Databricks Lakehouse Platform.”— Pat Lee, Vice President, Strategic Partnerships at NVIDIA.
Get began right now with AI Runtime
That can assist you get began, we’ve put collectively a number of template notebooks and starter guides:
- Please see our documentation for detailed directions on setup and each day use..
- Starter templates for coaching recommender programs, basic ML fashions, fine-tuning LLMs and extra!
- Migration information from Traditional Compute GPU workloads to Serverless.
Please attain out to your account staff to study extra or when you’ve got any questions!

{kind=link}