
{kind=link}
Fashionable producers face an more and more advanced problem: implementing clever decision-making methods that reply to real-time operational knowledge whereas sustaining safety and efficiency requirements. The quantity of sensor knowledge and operational complexity calls for AI-powered options that course of info regionally for instant responses whereas leveraging cloud sources for advanced duties.The business is at a crucial juncture the place edge computing and AI converge. Small Language Fashions (SLMs) are light-weight sufficient to run on constrained GPU {hardware} but highly effective sufficient to ship context-aware insights. Not like Massive Language Fashions (LLMs), SLMs match throughout the energy and thermal limits of business PCs or gateways, making them superb for manufacturing facility environments the place sources are restricted and reliability is paramount. For the aim of this weblog publish, assume a SLM has roughly 3 to fifteen billion parameters.
This weblog focuses on Open Platform Communications Unified Structure (OPC-UA) as a consultant manufacturing protocol. OPC-UA servers present standardized, real-time machine knowledge that SLMs operating on the edge can eat, enabling operators to question tools standing, interpret telemetry, or entry documentation immediately—even with out cloud connectivity.
AWS IoT Greengrass allows this hybrid sample by deploying SLMs along with AWS Lambda features on to OPC-UA gateways. Native inference ensures responsiveness for safety-critical duties, whereas the cloud handles fleet-wide analytics, multi-site optimization, or mannequin retraining underneath stronger safety controls.
This hybrid strategy opens prospects throughout industries. Automakers might run SLMs in automobile compute items for pure voice instructions and enhanced driving expertise. Power suppliers might course of SCADA sensor knowledge regionally in substations. In gaming, SLMs might run on gamers’ gadgets to energy companion AI in video games. Past manufacturing, larger training establishments might use SLMs to offer personalised studying, proofreading, analysis help and content material technology.
On this weblog, we’ll have a look at find out how to deploy SLMs to the sting seamlessly and at scale utilizing AWS IoT Greengrass.
The answer makes use of AWS IoT Greengrass to deploy and handle SLMs on edge gadgets, with Strands Brokers offering native agent capabilities. The providers used embody:
- AWS IoT Greengrass: An open-source edge software program and cloud service that allows you to deploy, handle and monitor machine software program.
- AWS IoT Core: Service enabling you to attach IoT gadgets to AWS cloud.
- Amazon Easy Storage Service (S3): A extremely scalable object storage which helps you to to retailer and retrieve any quantity of knowledge.
- Strands Brokers: A light-weight Python framework for operating multi-agent methods utilizing cloud and native inference.
We display the agent capabilities within the code pattern utilizing an industrial automation situation. We offer an OPC-UA simulator which defines a manufacturing facility consisting of an oven and a conveyor belt in addition to upkeep runbooks because the supply of the commercial knowledge. This answer may be prolonged to different use circumstances through the use of different agentic instruments.The next diagram exhibits the high-level structure:
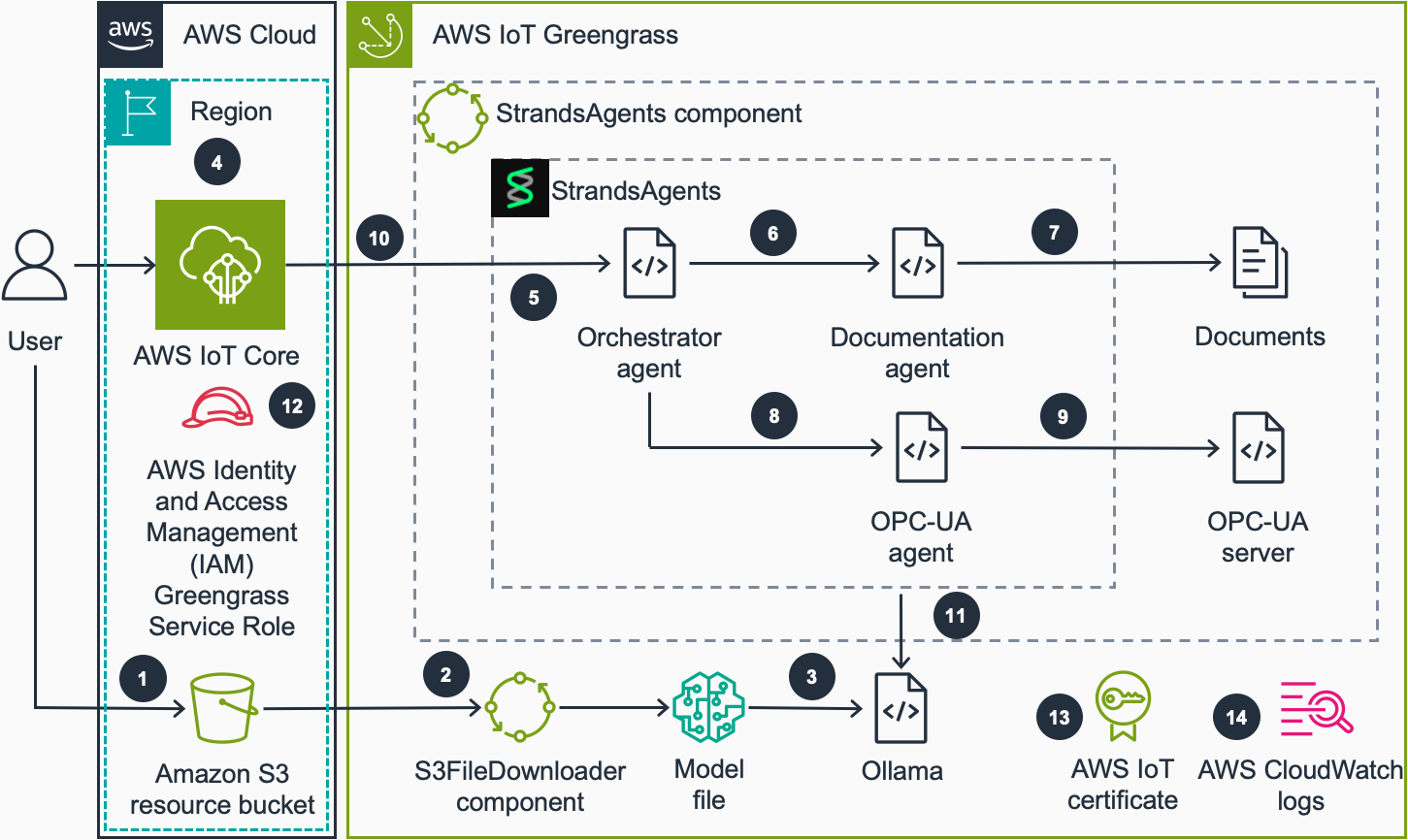
- Consumer uploads a mannequin file in GPT-Generated Unified Format (GGUF) format to an Amazon S3 bucket which AWS IoT Greengrass gadgets have entry to.
- The gadgets within the fleet obtain a file obtain job. S3FileDownloader part processes this job and downloads the mannequin file to the machine from the S3 bucket. The S3FileDownloader part can deal with giant file sizes, usually wanted for SLM mannequin information that exceed the native Greengrass part artifact measurement limits.
- The mannequin file in GGUF format is loaded into Ollama when Strands Brokers part makes the primary name to Ollama. GGUF is a binary file format used for storing LLMs. Ollama is a software program which masses the GGUF mannequin file and runs inference. The mannequin title is specified within the recipe.yaml file of the part.
- The person sends a question to the native agent by publishing a payload to a tool particular agent matter in AWS IoT MQTT dealer.
- After receiving the question, the part leverages the Strands Brokers SDK‘s model-agnostic orchestration capabilities. The Orchestrator Agent perceives the question, causes concerning the required info sources, and acts by calling the suitable specialised brokers (Documentation Agent, OPC-UA Agent, or each) to collect complete knowledge earlier than formulating a response.
- If the question is said to an info that may be discovered within the documentation, Orchestrator Agent calls Documentation Agent.
- Documentation Agent finds the data from the offered paperwork and returns it to Orchestrator Agent.
- If the question is said to present or historic machine knowledge, Orchestrator Agent will name OPC-UA Agent.
- OPC-UA Agent makes a question to the OPC-UA server relying on the person question and returns the info from server to Orchestrator Agent.
- Orchestrator Agent types a response primarily based on the collected info. Strands Brokers part publishes the response to a tool particular agent response matter in AWS IoT MQTT dealer.
- The Strands Brokers SDK allows the system to work with regionally deployed basis fashions via Ollama on the edge, whereas sustaining the choice to modify to cloud-based fashions like these in Amazon Bedrock when connectivity is obtainable.
- AWS IAM Greengrass service function gives entry to the S3 useful resource bucket to obtain fashions to the machine.
- AWS IoT certificates connected to the IoT factor permits Strands Brokers part to obtain and publish MQTT payloads to AWS IoT Core.
- Greengrass part logs the part operation to the native file system. Optionally, AWS CloudWatch logs may be enabled to watch the part operation within the CloudWatch console.
Earlier than beginning this walkthrough, guarantee you may have:
On this publish, you’ll:
- Deploy Strands Brokers as an AWS IoT Greengrass part.
- Obtain SLMs to edge gadgets.
- Take a look at the deployed agent.
Part deployment
First, let’s deploy the StrandsAgentGreengrass part to your edge machine.Clone the Strands Brokers repository:
Use Greengrass Improvement Package (GDK) to construct and publish the part:
To publish the part, you could modify the area and bucket values in gdk-config.json file. The advisable artifact bucket worth is greengrass-artifacts. GDK will generate a bucket in greengrass-artifacts-
The part will seem within the AWS IoT Greengrass Elements Console. You possibly can check with Deploy your part documentation to deploy the part to your gadgets.
After the deployment, the part will run on the machine. It consists of Strands Brokers, an OPC-UA simulation server and pattern documentation. Strands Brokers makes use of Ollama server because the SLM inference engine. The part has OPC-UA and documentation instruments to retrieve the simulated real-time knowledge and pattern tools manuals for use by the agent.
If you wish to check the part in an Amazon EC2 occasion, you should utilize IoTResources.yaml Amazon CloudFormation template to deploy a GPU occasion with needed software program put in. This template additionally creates sources for operating Greengrass. After the deployment of the stack, a Greengrass Core machine will seem within the AWS IoT Greengrass console. The CloudFormation stack may be discovered underneath supply/cfn folder within the repository. You possibly can learn find out how to deploy a CloudFormation stack in Create a stack from the CloudFormation console documentation.
Downloading the mannequin file
The part wants a mannequin file in GGUF format for use by Ollama because the SLM. That you must copy the mannequin file underneath /tmp/vacation spot/ folder within the edge machine. The mannequin file title have to be mannequin.gguf, in the event you use the default ModelGGUFName parameter within the recipe.yaml file of the part.
In case you don’t have a mannequin file in GGUF format, you possibly can obtain one from Hugging Face, for instance Qwen3-1.7B-GGUF. In a real-world software, this is usually a fine-tuned mannequin which solves particular enterprise issues on your use case.
(Optionally available) Use S3FileDownloader to obtain mannequin information
To handle mannequin distribution to edge gadgets at scale, you should utilize the S3FileDownloader AWS IoT Greengrass part. This part is especially worthwhile for deploying giant information in environments with unreliable connectivity, because it helps computerized retry and resume capabilities. Because the mannequin information may be giant, and machine connectivity just isn’t dependable in lots of IoT use circumstances, this part will help you to deploy fashions to your machine fleets reliably.
After deploying S3FileDownloader part to your machine, you possibly can publish the next payload to issues/ matter through the use of AWS IoT MQTT Take a look at Consumer. The file can be downloaded from the Amazon S3 bucket and put into /tmp/vacation spot/ folder within the edge machine:
In case you used the CloudFormation template offered within the repository, you should utilize the S3 bucket created by this template. Check with the output of the CloudFormation stack deployment to view the title of the bucket.
Testing the native agent
As soon as the deployment is full and the mannequin is downloaded, we are able to check the agent via the AWS IoT Core MQTT Take a look at Consumer. Steps:
- Subscribe to
issues/matter to view the response of the agent./# - Publish a check question to the enter matter
issues/:/agent/question
- You must obtain responses on a number of subjects:
- Remaining response matter (
issues/) which accommodates the ultimate response of the Orchestrator Agent:/agent/response
- Remaining response matter (
-
- Sub-agent responses (
issues/) which accommodates the response from middleman brokers corresponding to OPC-UA Agent and Documentation Agent:/agent/subagent
- Sub-agent responses (
The agent will course of your question utilizing the native SLM and supply responses primarily based on each the OPC-UA simulated knowledge and the tools documentation saved regionally.For demonstration functions, we use the AWS IoT Core MQTT check consumer as an easy interface to speak with the native machine. In manufacturing, Strands Brokers can run absolutely on the machine itself, eliminating the necessity for any cloud interplay.
Monitoring the part
To watch the part’s operation, you possibly can join remotely to your AWS IoT Greengrass machine and test the part logs:
This can present you the real-time operation of the agent, together with mannequin loading, question processing, and response technology. You possibly can study extra about Greengrass logging system in Monitor AWS IoT Greengrass logs documentation.
Go to AWS IoT Core Greengrass console to delete the sources created on this publish:
- Go to Deployments, select the deployment that you just used for deploying the part, then revise the deployment by eradicating the Strands Brokers part.
- If in case you have deployed S3FileDownloader part, you possibly can take away it from the deployment as defined within the earlier step.
- Go to Elements, select the Strands Brokers part and select ‘Delete model’ to delete the part.
- If in case you have created S3FileDownloader part, you possibly can delete it as defined within the earlier step.
- In case you deployed the CloudFormation stack to run the demo in an EC2 occasion, delete the stack from AWS CloudFormation console. Notice that the EC2 occasion will incur hourly prices till it’s stopped or terminated.
- In case you don’t want the Greengrass core machine, you possibly can delete it from Core gadgets part of Greengrass console.
- After deleting Greengrass Core machine, delete the IoT certificates connected to the core factor. To search out the factor certificates, go to AWS IoT Issues console, select the IoT factor created on this information, view the Certificates tab, select the connected certificates, select Actions, then select Deactivate and Delete.
On this publish, we confirmed find out how to run a SLM regionally utilizing Ollama built-in via Strands Brokers on AWS IoT Greengrass. This workflow demonstrated how light-weight AI fashions may be deployed and managed on constrained {hardware} whereas benefiting from cloud integration for scale and monitoring. Utilizing OPC-UA as our manufacturing instance, we highlighted how SLMs on the edge allow operators to question tools standing, interpret telemetry, and entry documentation in actual time—even with restricted connectivity. The hybrid mannequin ensures crucial choices occur regionally, whereas advanced analytics and retraining are dealt with securely within the cloud.This structure may be prolonged to create a hybrid cloud-edge AI agent system, the place edge AI brokers (utilizing AWS IoT Greengrass) seamlessly combine with cloud-based brokers (utilizing Amazon Bedrock). This allows distributed collaboration: edge brokers handle real-time, low-latency processing and instant actions, whereas cloud brokers deal with advanced reasoning, knowledge analytics, mannequin refinement, and orchestration.
In regards to the authors
 Ozan Cihangir is a Senior Prototyping Engineer at AWS Specialists & Companions Group. He helps clients to construct revolutionary options for his or her rising know-how tasks within the cloud.
Ozan Cihangir is a Senior Prototyping Engineer at AWS Specialists & Companions Group. He helps clients to construct revolutionary options for his or her rising know-how tasks within the cloud.
 Luis Orus is a senior member of the AWS Specialists & Companions Group, the place he has held a number of roles – from constructing high-performing groups at world scale to serving to clients innovate and experiment rapidly via prototyping.
Luis Orus is a senior member of the AWS Specialists & Companions Group, the place he has held a number of roles – from constructing high-performing groups at world scale to serving to clients innovate and experiment rapidly via prototyping.
 Amir Majlesi leads the EMEA prototyping staff inside AWS Specialists & Companions Group. He has in depth expertise in serving to clients speed up cloud adoption, expedite their path to manufacturing and foster a tradition of innovation. By fast prototyping methodologies, Amir allows buyer groups to construct cloud native functions, with a concentrate on rising applied sciences corresponding to Generative & Agentic AI, Superior Analytics, Serverless and IoT.
Amir Majlesi leads the EMEA prototyping staff inside AWS Specialists & Companions Group. He has in depth expertise in serving to clients speed up cloud adoption, expedite their path to manufacturing and foster a tradition of innovation. By fast prototyping methodologies, Amir allows buyer groups to construct cloud native functions, with a concentrate on rising applied sciences corresponding to Generative & Agentic AI, Superior Analytics, Serverless and IoT.
 Jaime Stewart targeted his Options Architect Internship inside AWS Specialists & Companions Group round Edge Inference with SLMs. Jaime presently pursues a MSc in Synthetic Intelligence.
Jaime Stewart targeted his Options Architect Internship inside AWS Specialists & Companions Group round Edge Inference with SLMs. Jaime presently pursues a MSc in Synthetic Intelligence.