


In case you’re combating handbook information classification in your group, the brand new Amazon SageMaker Catalog AI agent can automate this course of for you. Most giant organizations face challenges with the handbook tagging of knowledge property, which doesn’t scale and is unreliable. In some instances, enterprise phrases aren’t utilized constantly throughout groups. Completely different teams identify and tag information property based mostly on native conventions. This creates a fragmented catalog the place discovery turns into unreliable and governance groups spend extra time normalizing metadata than governing.
On this submit, we present you the way to implement this automated classification to assist scale back the handbook tagging effort and enhance metadata consistency throughout your group.
Amazon SageMaker Catalog offers automated information classification that implies enterprise glossary phrases throughout information publishing. This helps to scale back the handbook tagging effort and enhance metadata consistency throughout organizations. This functionality analyzes desk metadata and schema data utilizing Amazon Bedrock language fashions to suggest related phrases from organizational enterprise glossaries. Information producers obtain AI-generated strategies for enterprise phrases outlined inside their glossaries. These strategies embody each useful phrases and delicate information classifications similar to PII and PHI, making it simple to tag their datasets with standardized vocabulary. Producers can settle for or modify these strategies earlier than publishing, facilitating constant terminology throughout information property and bettering information discoverability for enterprise customers.
The issue with handbook classification
Guide tagging doesn’t scale successfully. Information producers interpret enterprise phrases in a different way, particularly throughout domains. Crucial labels like PII and PHI get missed as a result of the publishing workflow is already complicated. After property enter the catalog with inconsistent terminology, search performance and entry controls shortly degrade.The answer isn’t solely higher coaching—it’s making the classification course of predictable and constant.
How automated classification works
The aptitude runs straight contained in the publish workflow:
- The catalog seems to be on the desk’s construction—column names, sorts, no matter metadata exists.
- That construction is distributed to an Amazon Bedrock mannequin that matches patterns towards the group’s glossary.
- Producers obtain a set of strategies from the outlined enterprise glossary phrases for classification which may embody each useful and sensitive-data glossary phrases.
- They settle for or modify the strategies earlier than publishing.
- The ultimate record is written into the asset’s metadata utilizing the managed vocabulary.
The mannequin evaluates column names, information sorts, schema patterns, and current metadata. It maps these indicators to the phrases outlined within the group’s glossary. The strategies are generated inline throughout publishing, with no separate Extract, Rework and Load (ETL) or batch processes to take care of. The accepted phrases develop into a part of the asset’s metadata and move into downstream catalog operations instantly.
Beneath the hood: clever agent-based classification
Automated enterprise glossary task goes past easy metadata lookups utilizing a reasoning-driven strategy. The AI agent features like a digital information steward, following human-like reasoning patterns similar to:
- Opinions asset particulars and context
- Searches the catalog for related phrases
- Evaluates whether or not outcomes make sense
- Refines technique if preliminary searches don’t floor applicable phrases
- Learns from every step to enhance suggestions
Key approaches:
Reasoning over static queries – The agent interprets asset attributes and context reasonably than treating metadata as a set index, producing dynamic search intents as a substitute of counting on predefined queries.
Iterative adaptive search – When preliminary outcomes are weak, the agent robotically adjusts queries—broadening, narrowing, or shifting phrases by way of a suggestions loop that helps enhance discovery high quality.
Structured semantic search – The agent performs semantic querying throughout entity sorts, applies filtering and relevance scoring, and conducts multi-directional exploration till robust matches are discovered.
This enables the agent to discover a number of instructions till robust matches are discovered, bettering recall and precision over static strategies like direct vector search when asset metadata is incomplete or ambiguous.
Issues to bear in mind
This characteristic is barely as robust because the glossary it sits on high of. If the glossary is incomplete or inconsistent, the strategies replicate that. Producers ought to nonetheless evaluation every suggestion, particularly for regulatory labels. Governance groups ought to monitor how usually strategies are accepted or overridden to grasp mannequin accuracy and glossary gaps.
Stipulations
To comply with alongside, you need to have an Amazon SageMaker Unified Studio area arrange with a site proprietor or area unit proprietor permissions. It’s essential to have a undertaking that you should utilize to publish property. For directions on establishing a brand new area, check with the SageMaker Unified Studio Getting began information. We will even use Amazon Redshift to catalog information. In case you are not acquainted, learn Study Amazon Redshift ideas to be taught extra.
Step 1: Outline enterprise glossary and phrases
AI suggestions recommend phrases solely from glossaries and definitions already current within the system. As a primary step we create high-quality, well-described glossary entries so the AI can return correct and significant strategies.
We create the next enterprise glossaries in our area. For details about the way to create a enterprise glossary, see Create a enterprise glossary in Amazon SageMaker Unified Studio.
Area: Phrases – Buyer Profile, Coverage, Order, Bill.
The next is the view of ‘Area’ enterprise glossary with all phrases added.
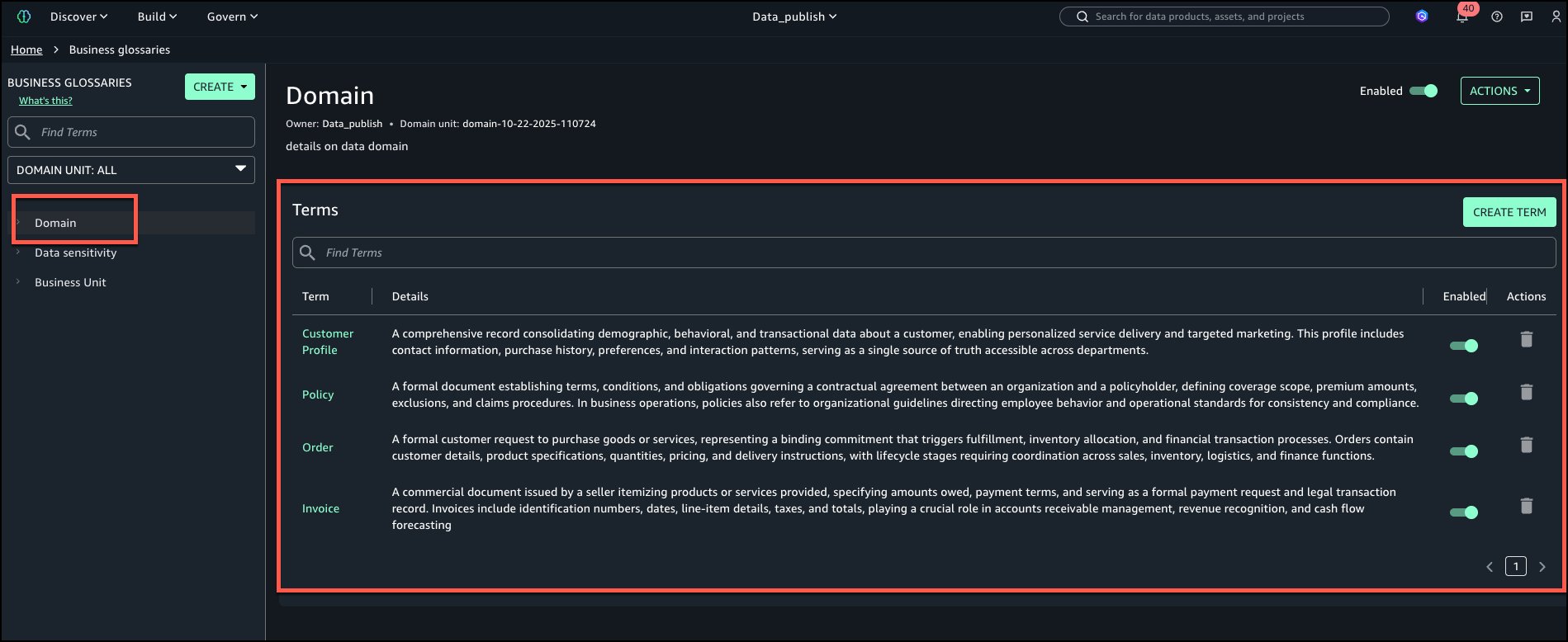
Information sensitivity: Phrases – PII, PHI, Confidential, Inner.
The next is the view of ‘Information sensitivity’ enterprise glossary with all phrases added.
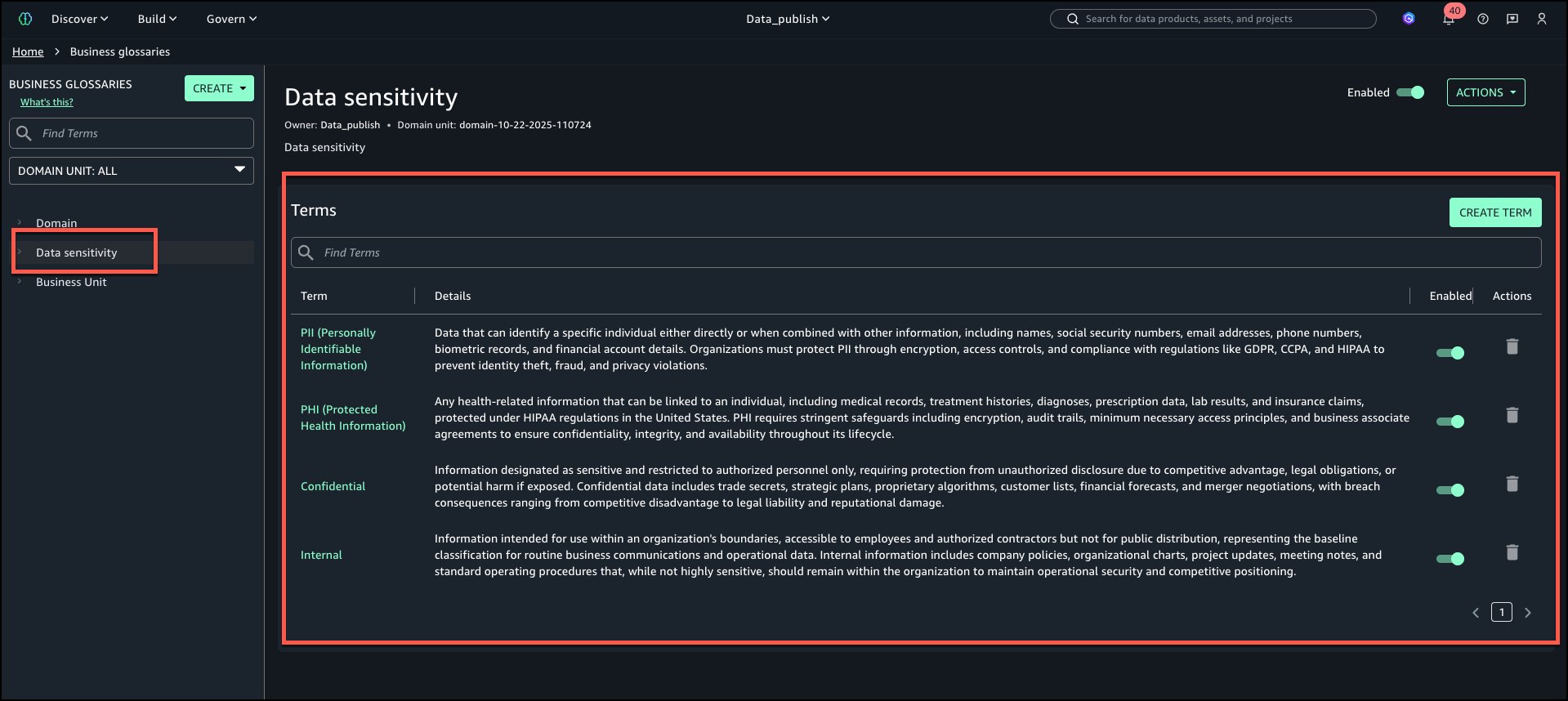
Enterprise Unit: Phrases – KYC, Credit score Danger, Advertising and marketing Analytics
The next is the view of ‘Enterprise Unit’ enterprise glossary with all phrases added.
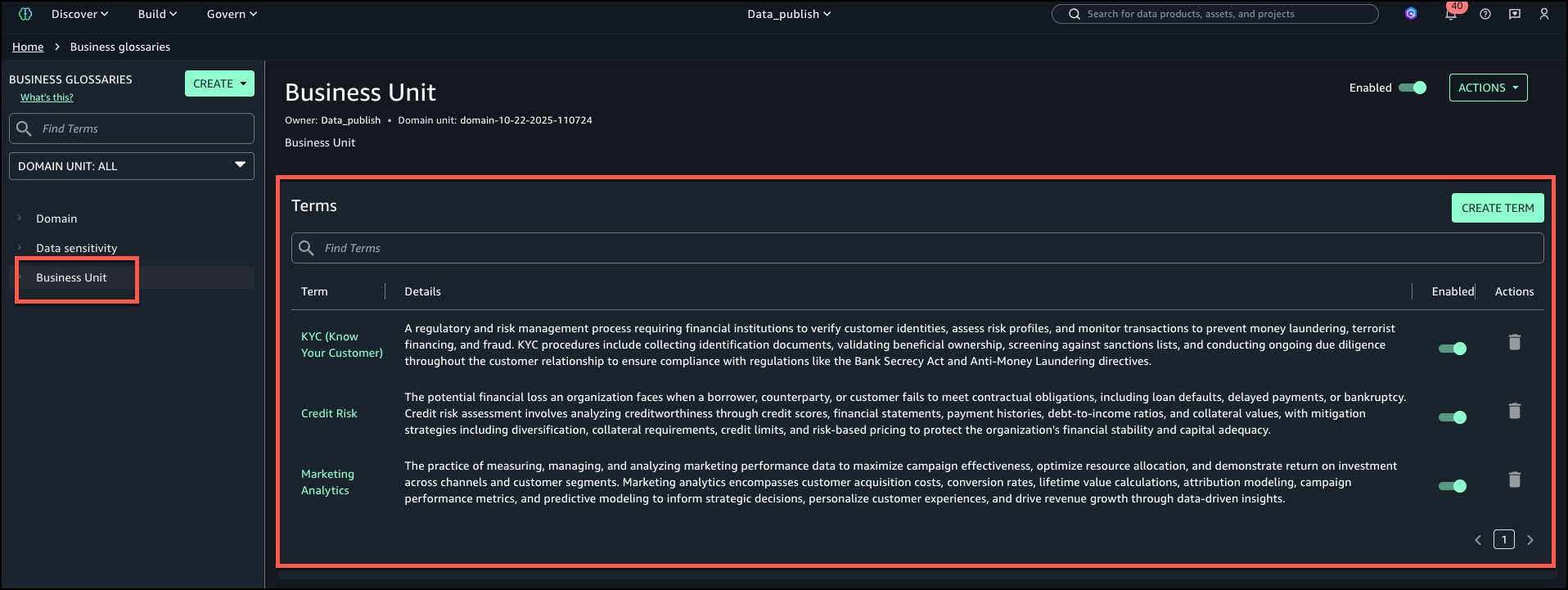
We suggest that you simply use glossary descriptions to make phrases unambiguous. Ambiguous or overlapping definitions confuse AI fashions and people equally.
Step 2: Create information property
Create the next desk in Amazon Redshift. For details about the way to convey Amazon Redshift information to Amazon SageMaker Catalog, see Amazon Redshift compute connections in Amazon SageMaker Unified Studio.
As soon as the Redshift is onboarded with above steps, navigate to Venture catalog from left navigation menu and select Information sources. Run the Information Supply so as to add the desk to Venture stock property.
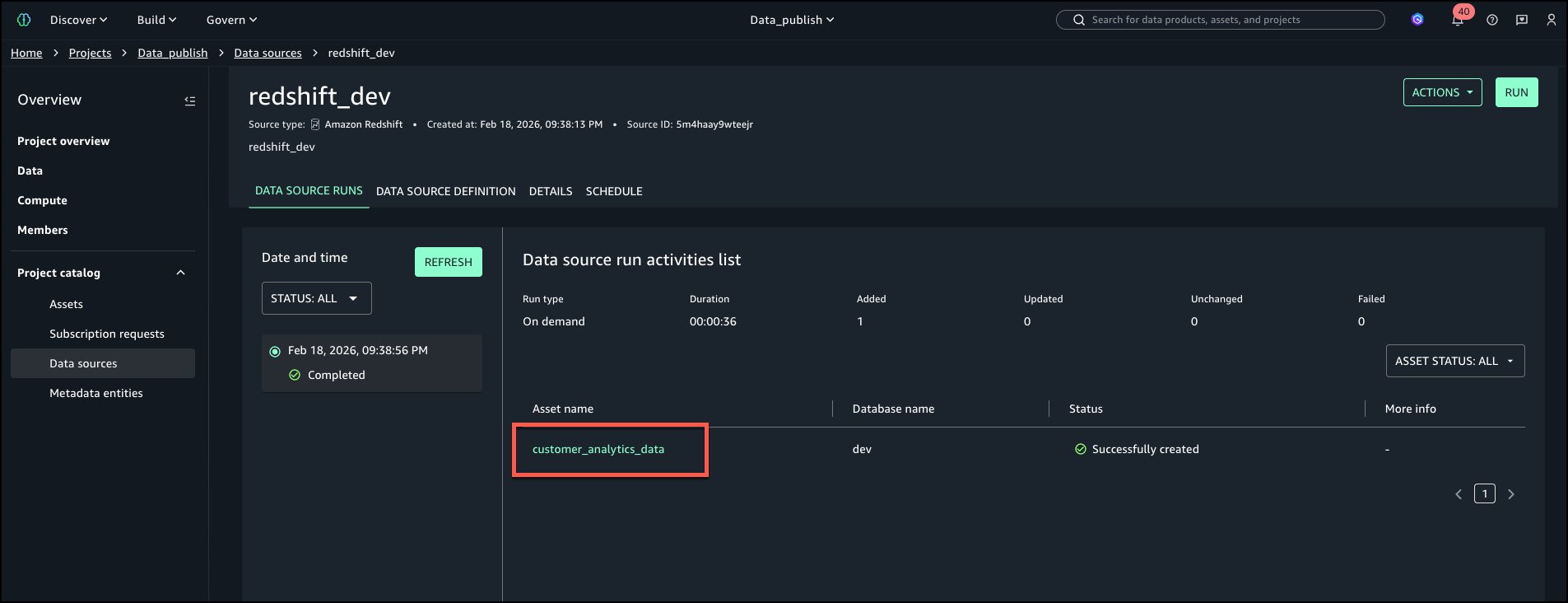
‘customer_analytics_data’ needs to be Venture Belongings stock.
Confirm navigating to ‘Venture catalog’ menu on the left and select ‘Belongings’.
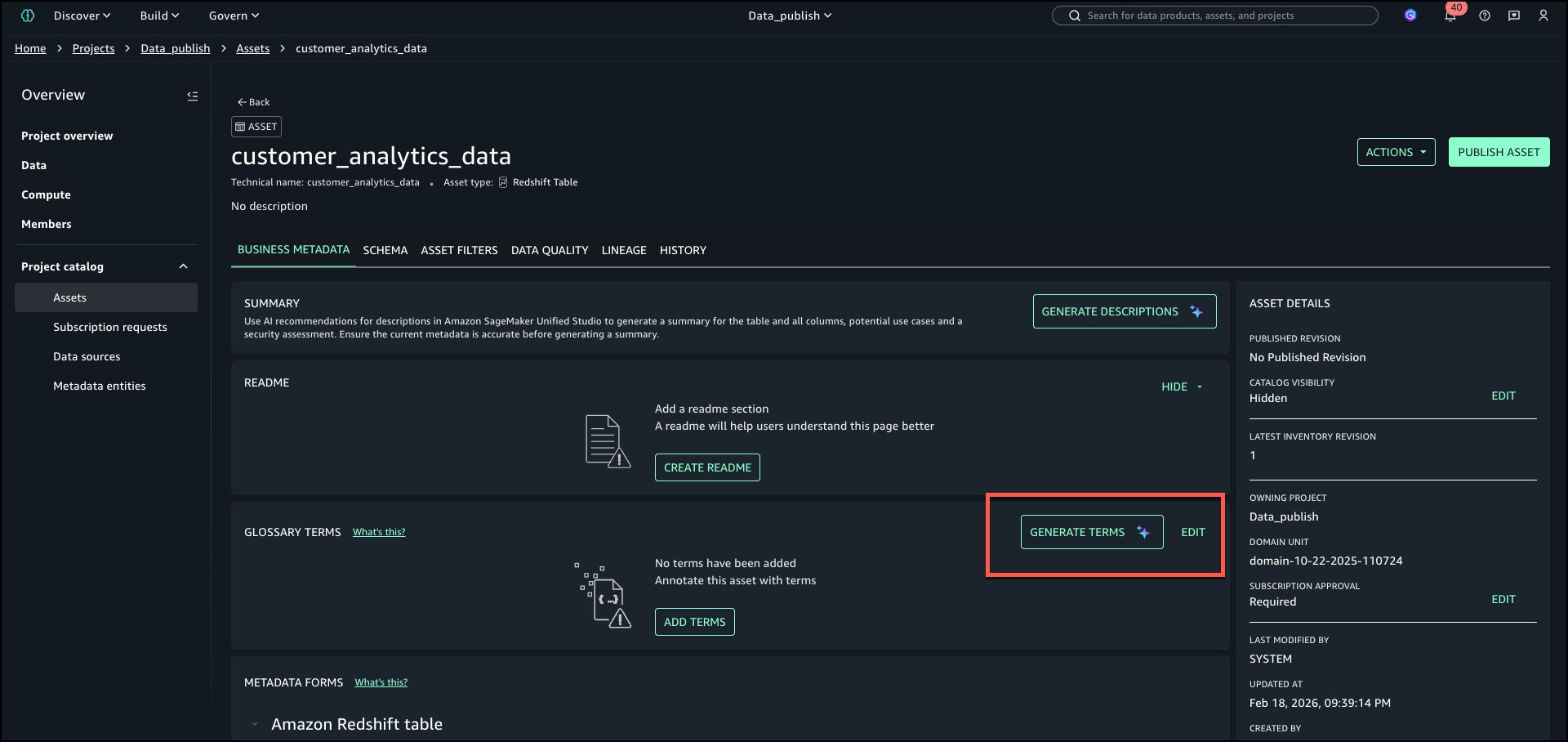
Step 3: Generate classification suggestions
To robotically generate phrases, choose GENERATE TERMS in ‘GLOSSARY TERMS’ part of the asset.
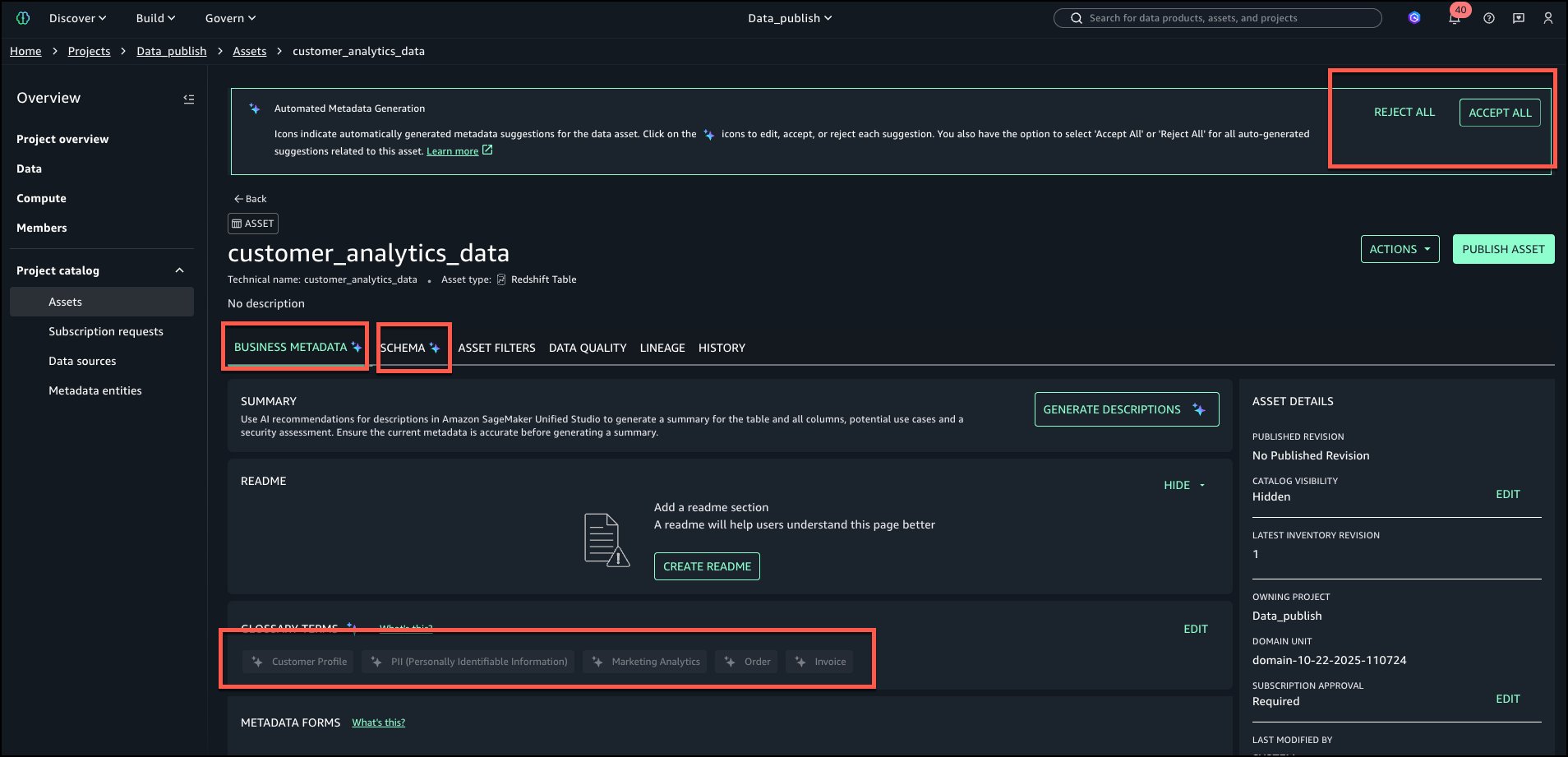
AI suggestions for glossary phrases robotically analyze asset metadata and context to find out probably the most related enterprise glossary phrases for every asset and its columns. As an alternative of counting on handbook tagging or static guidelines, it causes concerning the information and performs iterative searches throughout what already exists within the setting to establish probably the most related glossary time period ideas.
After suggestions are generated, evaluation the phrases each at desk and column degree. Desk degree recommended phrases will be seen as proven within the following picture:
Choose the SCHEMA tab to evaluation column degree tags as proven within the following picture:
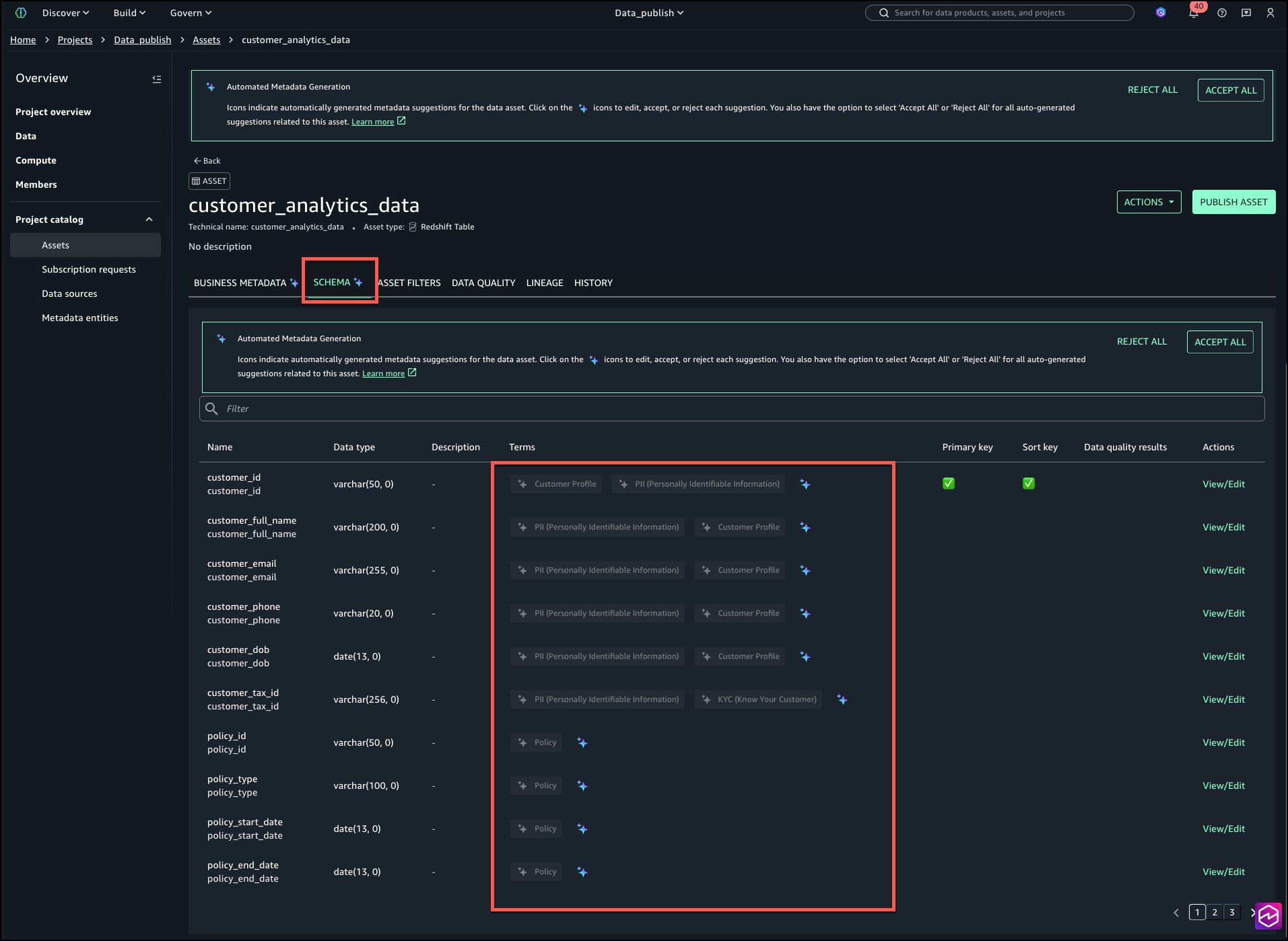
Overview and settle for individually by deciding on the AI icon proven in beneath picture.
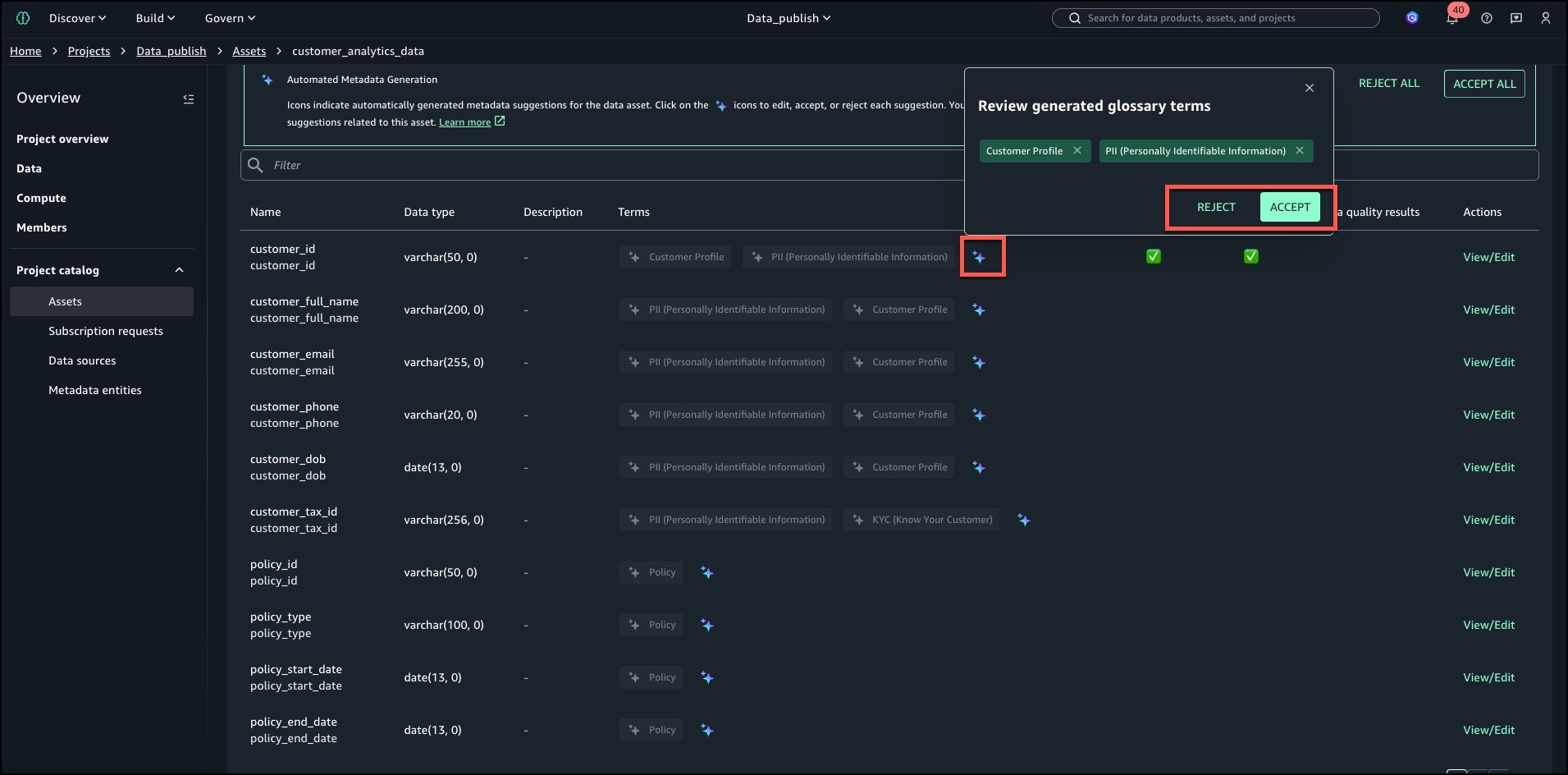
On this case, we choose ACCEPT ALL after which choose PUBLISH ASSET as proven beneath.
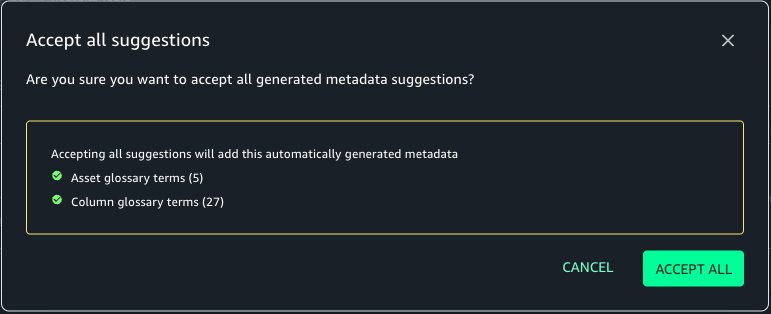
The tags are actually added to the asset and columns with out handbook search and addition. Choose PUBLISH ASSET.
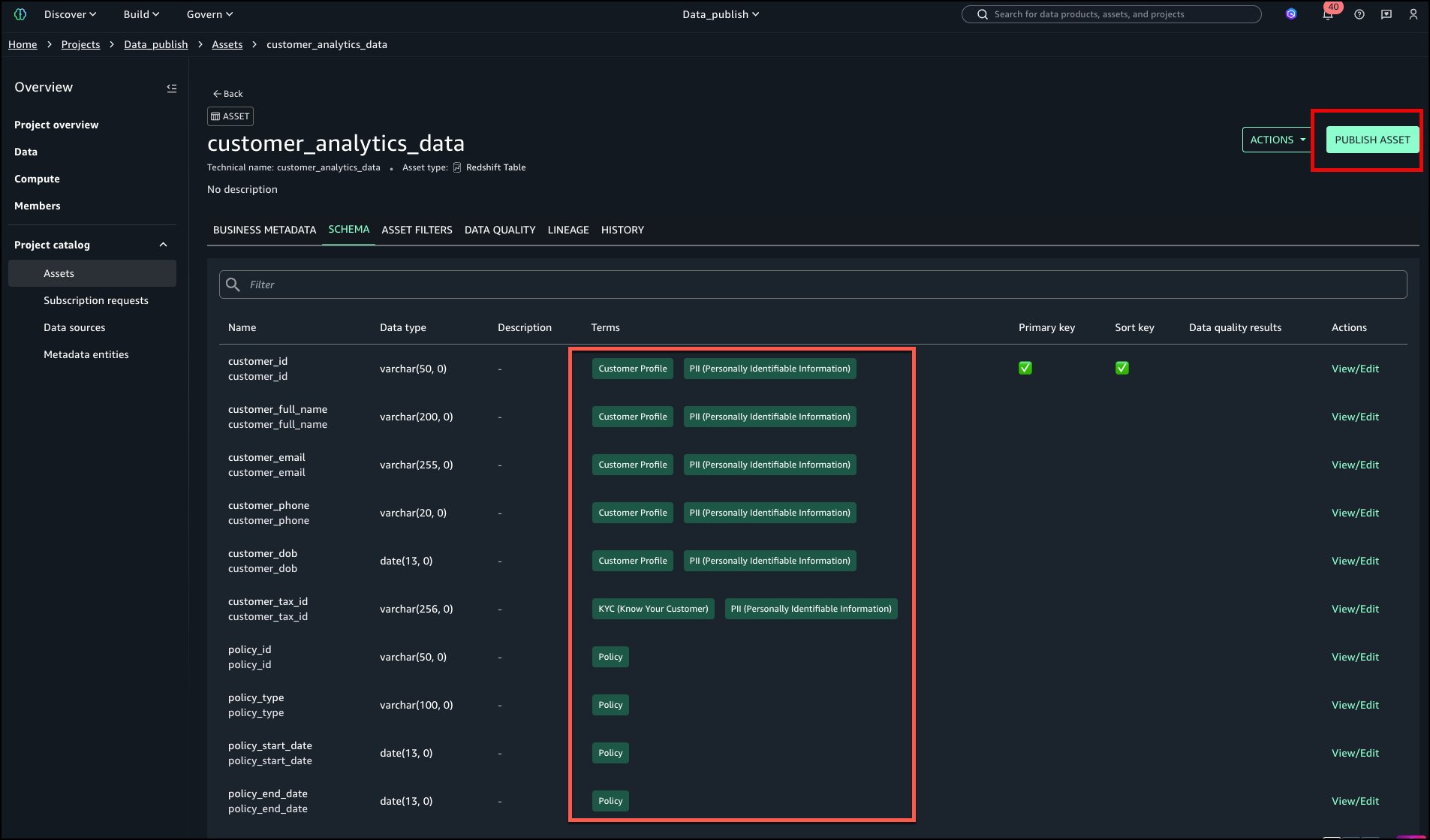
The asset is now revealed to the catalog as proven within the following picture within the higher left nook.
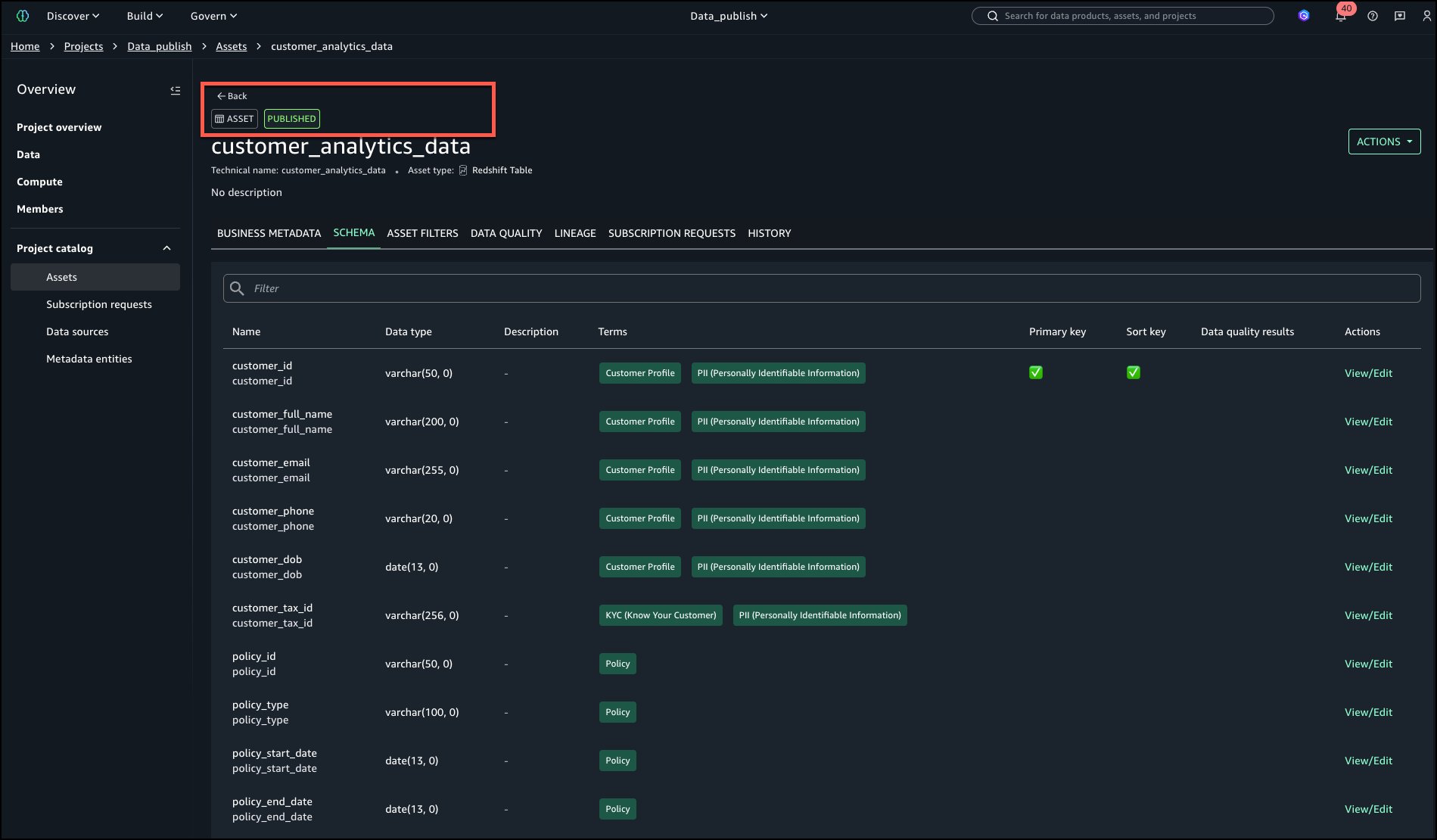
Step 4: Enhance information discovery
Customers can now expertise enhanced search outcomes and discover property within the catalog based mostly on the related phrases.
Browse by TermsUsers can now discover the catalog and filter by phrases as proven in left navigation “APPLY FILTER” part
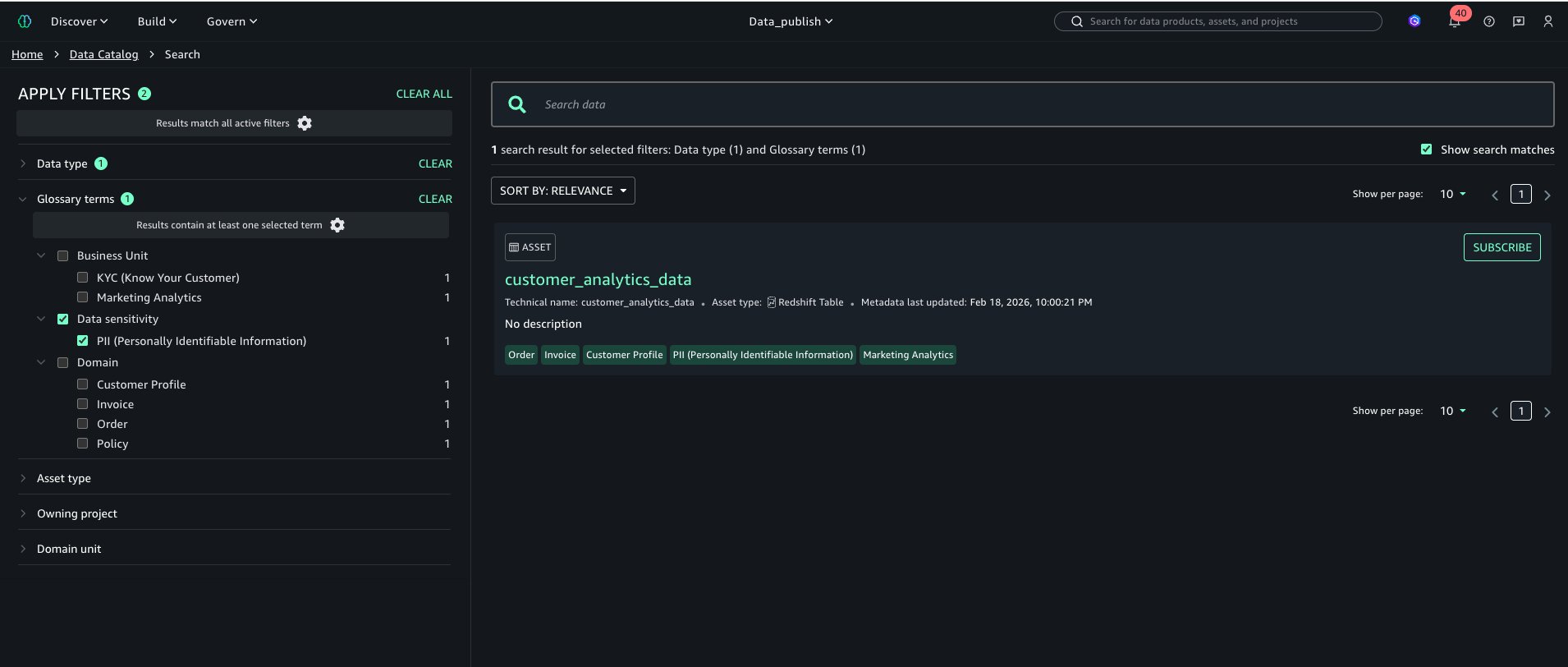
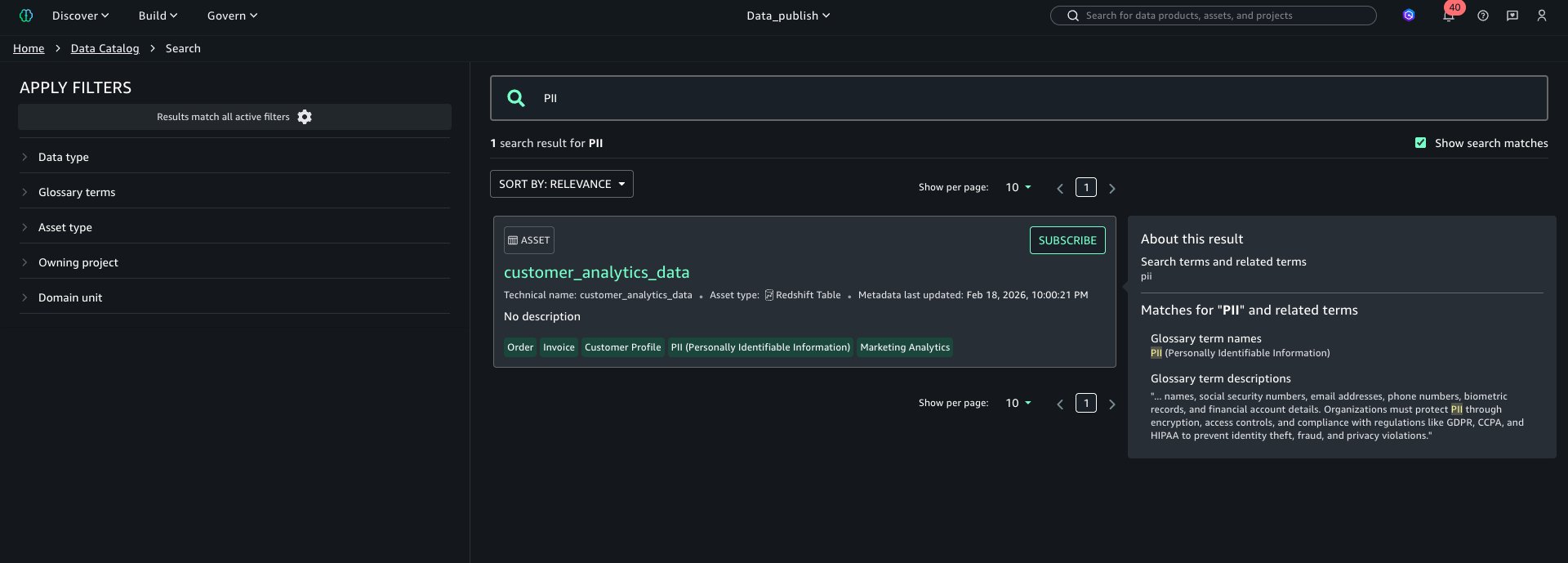
Search and FilterUsers also can search property by glossary phrases as proven beneath:
Cleanup
Conclusion
By standardizing terminology at publication, organizations can scale back metadata drift and enhance discovery reliability. The characteristic integrates with current workflows, requiring minimal course of adjustments whereas serving to ship instant catalog consistency enhancements.
By tagging information at publication reasonably than correcting it later, information groups can spend much less time fixing metadata and extra time utilizing it. For extra data on SageMaker capabilities, see the Amazon SageMaker Catalog Consumer Information.
In regards to the authors

{kind=link}