

{kind=link}

|
Since we launched Amazon Nova customization in Amazon SageMaker AI at AWS NY Summit 2025, clients have been asking for a similar capabilities with Amazon Nova as they do once they customise open weights fashions in Amazon SageMaker Inference. Additionally they wished have extra management and adaptability in customized mannequin inference over occasion varieties, auto-scaling insurance policies, context size, and concurrency settings that manufacturing workloads demand.
At present, we’re saying the overall availability of customized Nova mannequin help in Amazon SageMaker Inference, a production-grade, configurable, and cost-efficient managed inference service to deploy and scale full-rank personalized Nova fashions. Now you can expertise an end-to-end customization journey to coach Nova Micro, Nova Lite, and Nova 2 Lite fashions with reasoning capabilities utilizing Amazon SageMaker Coaching Jobs or Amazon HyperPod and seamlessly deploy them with managed inference infrastructure of Amazon SageMaker AI.
With Amazon SageMaker Inference for customized Nova fashions, you possibly can cut back inference price by optimized GPU utilization utilizing Amazon Elastic Compute Cloud (Amazon EC2) G5 and G6 situations over P5 situations, auto-scaling primarily based on 5-minute utilization patterns, and configurable inference parameters. This characteristic permits deployment of personalized Nova fashions with continued pre-training, supervised fine-tuning, or reinforcement fine-tuning to your use instances. You may as well set superior configurations about context size, concurrency, and batch measurement for optimizing the latency-cost-accuracy tradeoff to your particular workloads.
Let’s see how one can deploy personalized Nova fashions on SageMaker AI real-time endpoints, configure inference parameters, and invoke your fashions for testing.
Deploy customized Nova fashions in SageMaker Inference
At AWS re:Invent 2025, we launched new serverless customization in Amazon SageMaker AI for well-liked AI fashions together with Nova fashions. With a couple of clicks, you possibly can seamlessly choose a mannequin and customization approach, and deal with mannequin analysis and deployment. If you have already got a skilled customized Nova mannequin artifact, you possibly can deploy the fashions on SageMaker Inference by the SageMaker Studio or SageMaker AI SDK.
Within the SageMaker Studio, select a skilled Nova mannequin in Fashions in your fashions within the Fashions menu. You’ll be able to deploy the mannequin by selecting Deploy button, SageMaker AI and Create new endpoint.
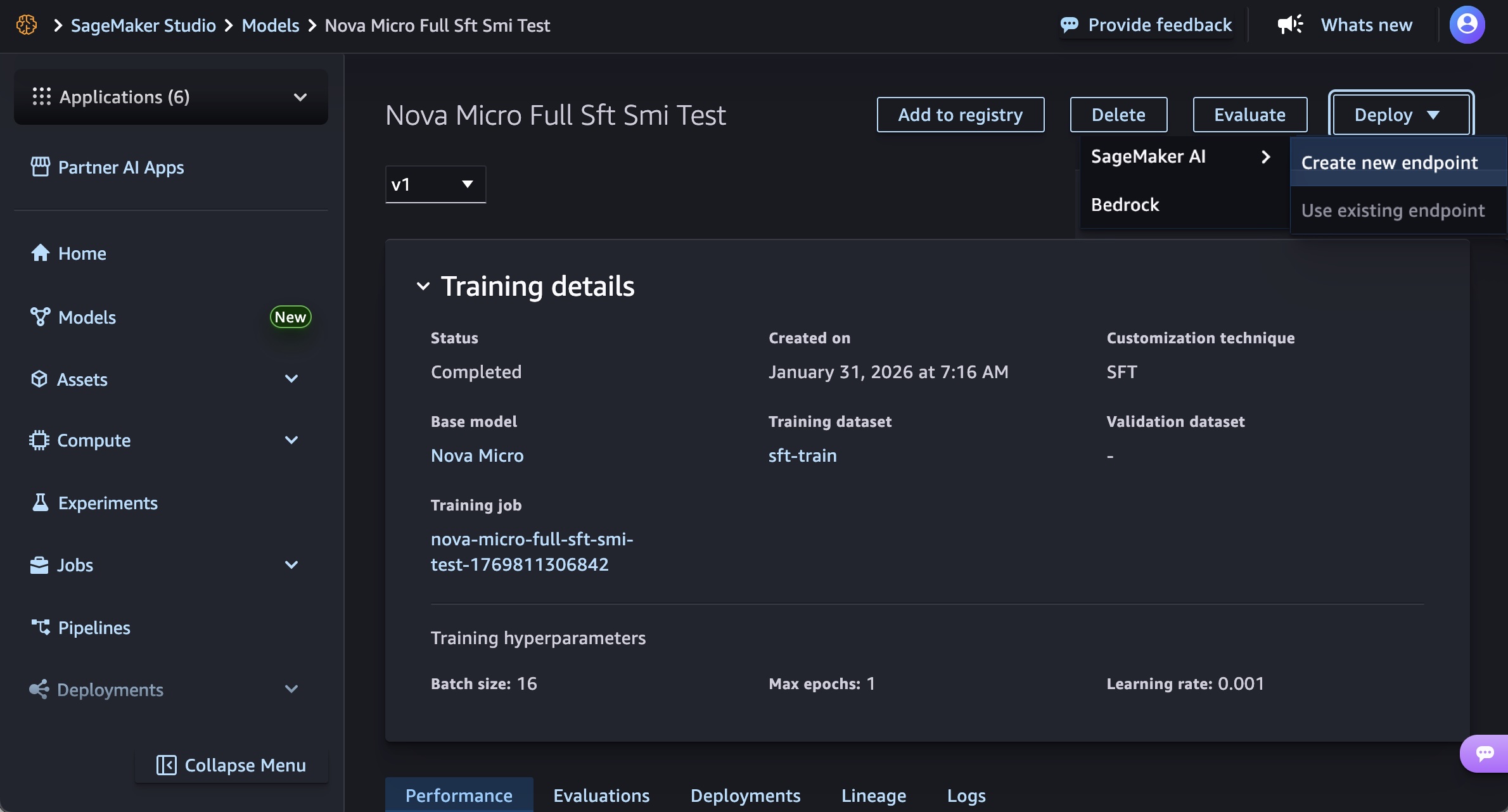
Select the endpoint title, occasion kind, and superior choices equivalent to occasion rely, max occasion rely, permission and networking, and Deploy button. At GA launch, you should utilize g5.12xlarge, g5.24xlarge, g5.48xlarge, g6.12xlarge, g6.24xlarge, g6.48xlarge, and p5.48xlarge occasion varieties for the Nova Micro mannequin, g5.48xlarge, g6.48xlarge, and p5.48xlarge for the Nova Lite mannequin, and p5.48xlarge for the Nova 2 Lite mannequin.
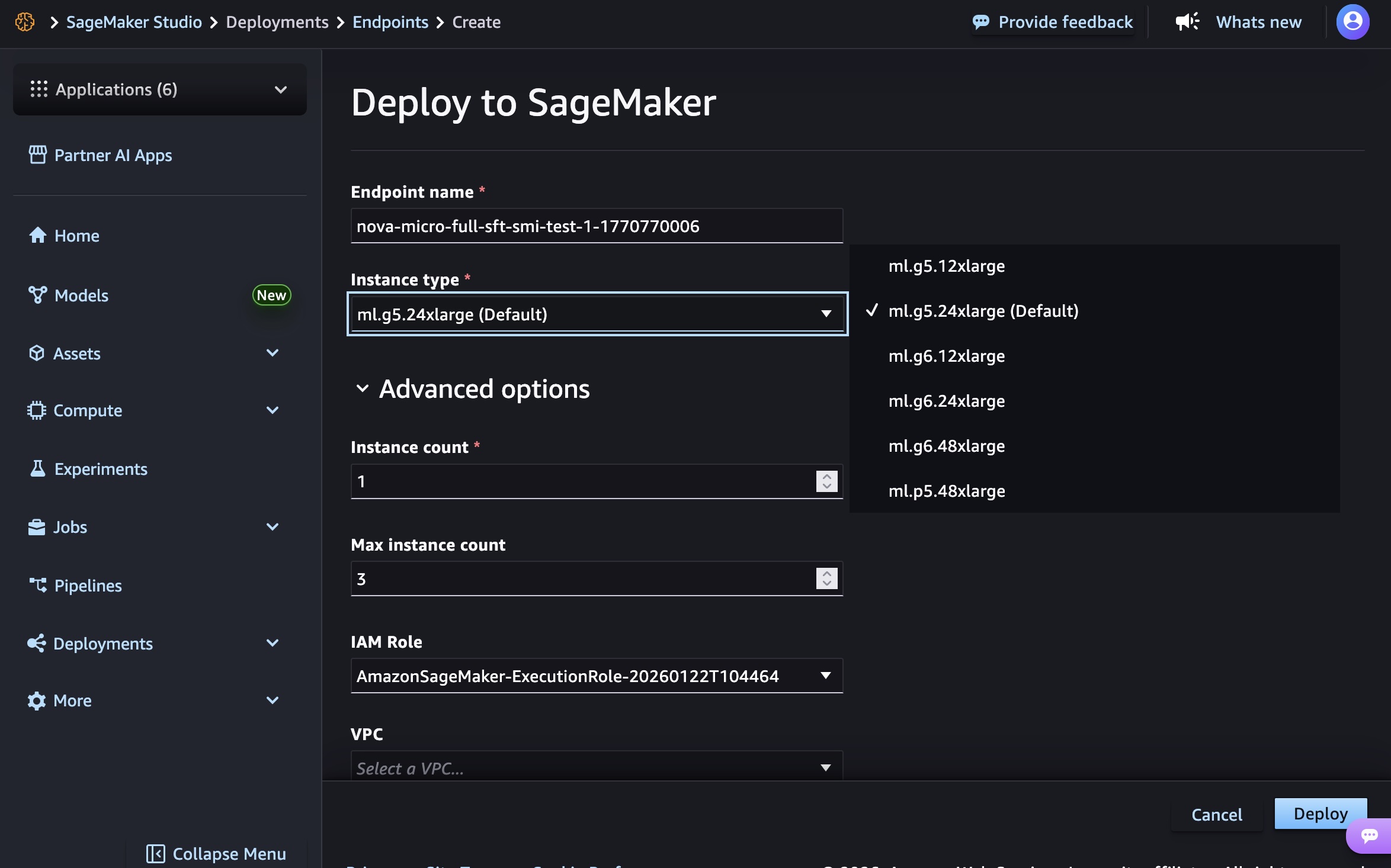
Creating your endpoint requires time to provision the infrastructure, obtain your mannequin artifacts, and initialize the inference container.
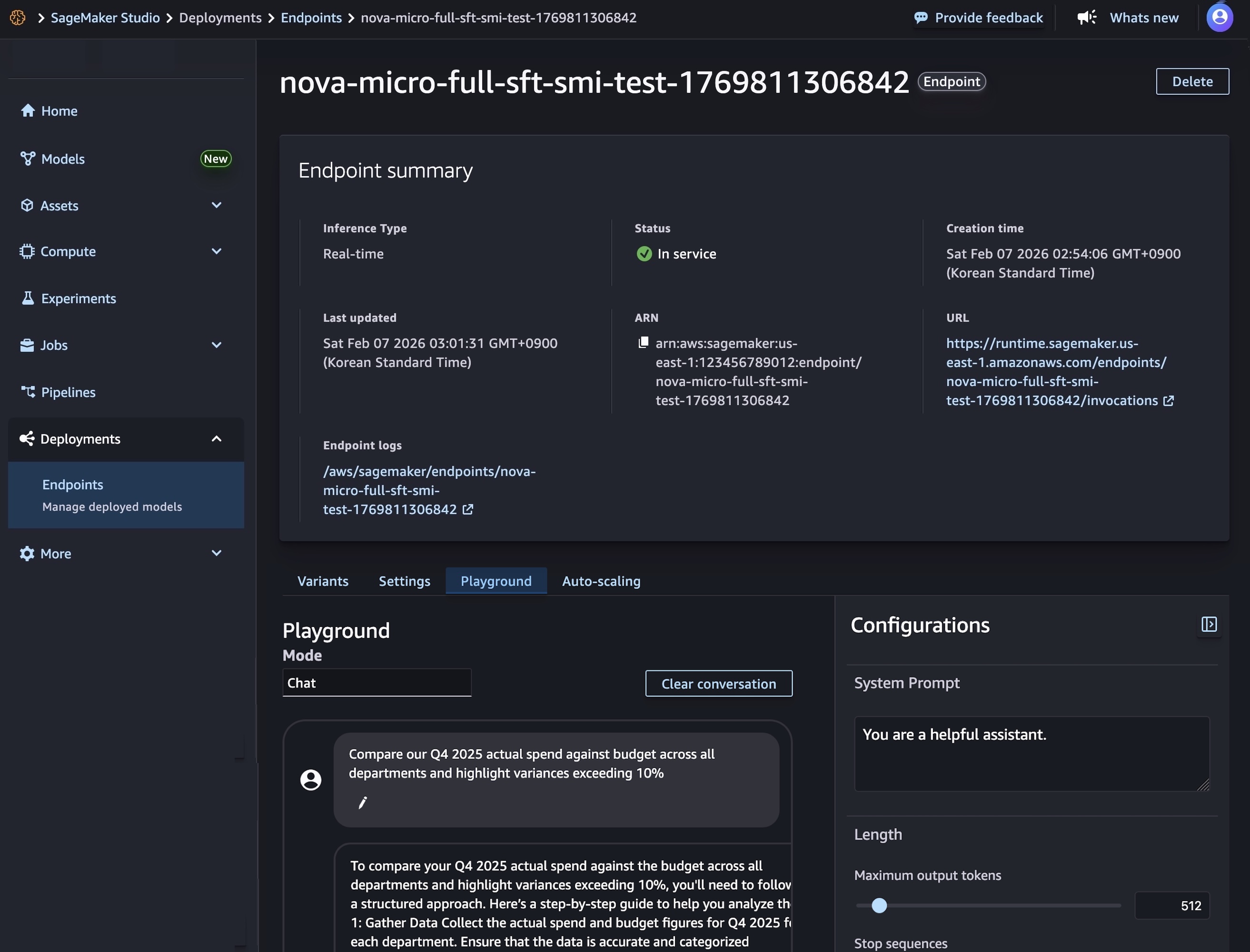
After mannequin deployment completes and the endpoint standing reveals InService, you possibly can carry out real-time inference utilizing the brand new endpoint. To check the mannequin, select the Playground tab and enter your immediate within the Chat mode.
You may as well use the SageMaker AI SDK to create two sources: a SageMaker AI mannequin object that references your Nova mannequin artifacts, and an endpoint configuration that defines how the mannequin can be deployed.
The next code pattern creates a SageMaker AI mannequin that references your Nova mannequin artifacts. For supported container pictures by Area, refer desk lists the container picture URIs:
# Create a SageMaker AI mannequin
model_response = sagemaker.create_model(
ModelName="Nova-micro-ml-g5-12xlarge",
PrimaryContainer={
'Picture': '708977205387.dkr.ecr.us-east-1.amazonaws.com/nova-inference-repo:v1.0.0',
'ModelDataSource': {
'S3DataSource': {
'S3Uri': 's3://your-bucket-name/path/to/mannequin/artifacts/',
'S3DataType': 'S3Prefix',
'CompressionType': 'None'
}
},
# Mannequin Parameters
'Setting': {
'CONTEXT_LENGTH': 8000,
'MAX_CONCURRENCY': 16,
'DEFAULT_TEMPERATURE': 0.0,
'DEFAULT_TOP_P': 1.0
}
},
ExecutionRoleArn=SAGEMAKER_EXECUTION_ROLE_ARN,
EnableNetworkIsolation=True
)
print("Mannequin created efficiently!")Subsequent, create an endpoint configuration that defines your deployment infrastructure and deploy your Nova mannequin by making a SageMaker AI real-time endpoint. This endpoint will host your mannequin and supply a safe HTTPS endpoint for making inference requests.
# Create Endpoint Configuration
production_variant = {
'VariantName': 'main',
'ModelName': 'Nova-micro-ml-g5-12xlarge',
'InitialInstanceCount': 1,
'InstanceType': 'ml.g5.12xlarge',
}
config_response = sagemaker.create_endpoint_config(
EndpointConfigName="Nova-micro-ml-g5-12xlarge-Config",
ProductionVariants= production_variant
)
print("Endpoint configuration created efficiently!")
# Deploy your Noval mannequin
endpoint_response = sagemaker.create_endpoint(
EndpointName="Nova-micro-ml-g5-12xlarge-endpoint",
EndpointConfigName="Nova-micro-ml-g5-12xlarge-Config"
)
print("Endpoint creation initiated efficiently!")
After the endpoint is created, you possibly can ship inference requests to generate predictions out of your customized Nova mannequin. Amazon SageMaker AI helps synchronous endpoints for real-time with streaming/non-streaming modes and asynchronous endpoints for batch processing.
For instance, the next code creates streaming completion format for textual content technology:
# Streaming chat request with complete parameters
streaming_request = {
"messages": [
{"role": "user", "content": "Compare our Q4 2025 actual spend against budget across all departments and highlight variances exceeding 10%"}
],
"max_tokens": 512,
"stream": True,
"temperature": 0.7,
"top_p": 0.95,
"top_k": 40,
"logprobs": True,
"top_logprobs": 2,
"reasoning_effort": "low", # Choices: "low", "excessive"
"stream_options": {"include_usage": True}
}
invoke_nova_endpoint(streaming_request)
def invoke_nova_endpoint(request_body):
"""
Invoke Nova endpoint with computerized streaming detection.
Args:
request_body (dict): Request payload containing immediate and parameters
Returns:
dict: Response from the mannequin (for non-streaming requests)
None: For streaming requests (prints output instantly)
"""
physique = json.dumps(request_body)
is_streaming = request_body.get("stream", False)
strive:
print(f"Invoking endpoint ({'streaming' if is_streaming else 'non-streaming'})...")
if is_streaming:
response = runtime_client.invoke_endpoint_with_response_stream(
EndpointName=ENDPOINT_NAME,
ContentType="software/json",
Physique=physique
)
event_stream = response['Body']
for occasion in event_stream:
if 'PayloadPart' in occasion:
chunk = occasion['PayloadPart']
if 'Bytes' in chunk:
knowledge = chunk['Bytes'].decode()
print("Chunk:", knowledge)
else:
# Non-streaming inference
response = runtime_client.invoke_endpoint(
EndpointName=ENDPOINT_NAME,
ContentType="software/json",
Settle for="software/json",
Physique=physique
)
response_body = response['Body'].learn().decode('utf-8')
outcome = json.hundreds(response_body)
print("✅ Response obtained efficiently")
return outcome
besides ClientError as e:
error_code = e.response['Error']['Code']
error_message = e.response['Error']['Message']
print(f"❌ AWS Error: {error_code} - {error_message}")
besides Exception as e:
print(f"❌ Sudden error: {str(e)}")To make use of full code examples, go to Getting began with customizing Nova fashions on SageMaker AI. To study extra about finest practices on deploying and managing fashions, go to Greatest practices for SageMaker AI.
Now out there
Amazon SageMaker Inference for customized Nova fashions is out there immediately in US East (N. Virginia) and US West (Oregon) AWS Areas. For Regional availability and a future roadmap, go to the AWS Capabilities by Area.
The characteristic helps Nova Micro, Nova Lite, and Nova 2 Lite fashions with reasoning capabilities, working on EC2 G5, G6, and P5 situations with auto-scaling help. You pay just for the compute situations you utilize, with per-hour billing and no minimal commitments. For extra info, go to Amazon SageMaker AI Pricing web page.
Give it a strive in Amazon SageMaker AI console and ship suggestions to AWS re:Submit for SageMaker or by your standard AWS Assist contacts.
— Channy